我正在尝试实现布鲁佐夫斯基算法来最小化我的DFA。以下是该算法的步骤:
DFA = d(r(d(r(NFA))))
其中 r() 是NFA的反转,D() 将NFA转换为DFA。
但我不明白 r() 的意思,在谷歌上搜索也没有给出太多信息。
有人能解释一下NFA中的 r() 吗?
如果有其他简单的算法或C++实现,请告诉我链接。
布鲁佐夫斯基算法通常被描述为:
minimized_DFA = subset(reverse(subset(reverse(NFA))))
其中subset表示子集构造(也称为powerset construction)。子集构造通过模拟NFA中每个等价状态集合的所有转换(由于epsilon转换)来构建DFA。
反转NFA需要以下步骤:
步骤2-4有效地交换了接受和起始状态的角色。
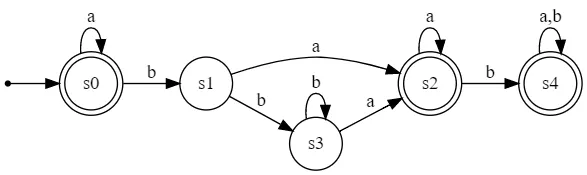
这是一个基于编译器课程Udacity测验的DFA最小化示例(使用NFA作为初始输入的步骤相同)。
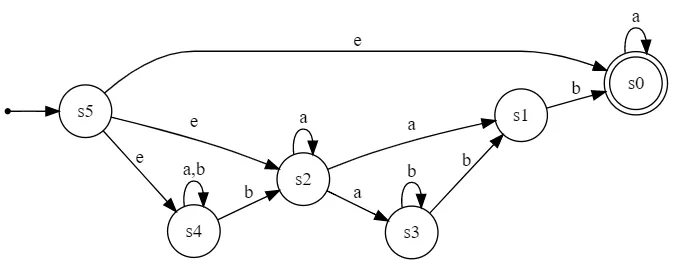
reverse(DFA):
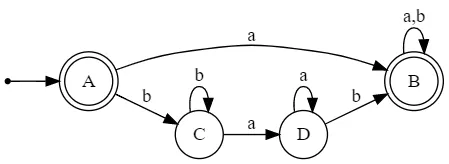
subset(reverse(DFA)):运行子集构造算法,构建一个DFA状态表格,表示从每个唯一的epsilon闭包可能的转换(^表示起始状态,$表示接受状态):
A = e-closure({s5}) = {s0,s2,s4}
B = e-closure({s0,s1,s2,s3,s4}) = {s0,s1,s2,s3,s4}
C = e-closure({s2,s4}) = {s2,s4}
D = e-closure({s1,s2,s3,s4}) = {s1,s2,s3,s4}
a b
-----------
A^$ B C
B$ B B
C D C
D D B
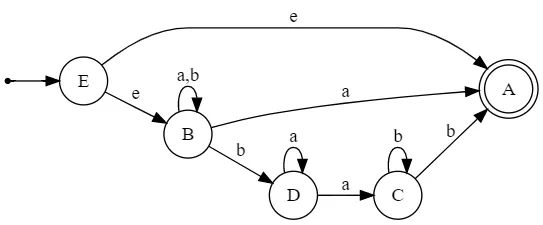
reverse(subset(reverse(DFA))):反转DFA。在消除公共前缀后,进行另一遍操作以消除公共后缀。
subset(reverse(subset(reverse(DFA)))):再次运行子集构造来最小化NFA。
A = e-closure({E}) = {A,B}
B = e-closure({B,D}) = {B,D}
C = e-closure({A,B,C,D} = {A,B,C,D}
a b
--------
A^$ A B
B C B
C$ C C
《编译器工程》第2版,作者:Cooper and Torczon。子集构造算法在第49页描述,Brzozowski算法在第75页。
Udacity的编译器理论和实践课程,第3课。
// initial DFA
digraph G {
rankdir=LR;
size="8,5"
node [shape=point]; qi;
node [shape=doublecircle]; s0 s2 s4;
node [shape=circle];
qi -> s0;
s0 -> s0 [label="a"];
s0 -> s1 [label="b"];
s1 -> s2 [label="a"];
s2 -> s2 [label="a"];
s2 -> s4 [label="b"];
s4 -> s4 [label="a,b"];
s1 -> s3 [label="b"];
s3 -> s3 [label="b"];
s3 -> s2 [label="a"];
}
// reverse(DFA)
digraph G {
rankdir=LR;
size="8,5"
node [shape=point]; qi;
node [shape=doublecircle]; s0;
node [shape=circle];
qi -> s5;
s0 -> s0 [label="a"];
s1 -> s0 [label="b"];
s2 -> s1 [label="a"];
s2 -> s2 [label="a"];
s4 -> s2 [label="b"];
s4 -> s4 [label="a,b"];
s3 -> s1 [label="b"];
s3 -> s3 [label="b"];
s2 -> s3 [label="a"];
s5 -> s2 [label="e"];
s5 -> s0 [label="e"];
s5 -> s4 [label="e"];
}
// subset(reverse(DFA))
digraph G {
rankdir=LR;
size="8,5"
node [shape=point]; qi;
node [shape=doublecircle]; A B;
node [shape=circle];
qi -> A;
A -> B [label="a"];
A -> C [label="b"];
B -> B [label="a,b"];
D -> B [label="b"];
C -> D [label="a"];
C -> C [label="b"];
D -> D [label="a"];
}
// reverse(subset(reverse(DFA)))
digraph G {
rankdir=LR;
size="8,5"
node [shape=point]; qi;
node [shape=doublecircle]; A;
node [shape=circle];
qi -> E;
B -> A [label="a"];
C -> A [label="b"];
B -> B [label="a,b"];
B -> D [label="b"];
D -> C [label="a"];
C -> C [label="b"];
D -> D [label="a"];
E -> A [label="e"];
E -> B [label="e"];
}
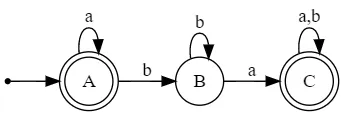
// subset(reverse(subset(reverse(DFA))))
digraph G {
rankdir=LR;
size="8,5"
node [shape=point]; qi;
node [shape=doublecircle]; A C;
node [shape=circle];
qi -> A;
A -> A [label="a"];
A -> B [label="b"];
B -> B [label="b"];
B -> C [label="a"];
C -> C [label="a,b"];
}
/* Create reversed edges */。因此,我认为 r() 反转了所有边的方向(并确保反转的自动机具有明确定义的起始状态)。
/* Create the new start state */后面的case语句时,我有一种印象,即该代码(reverse.c)创建了一个新的起始状态,并通过ε转换将其连接到原始NFA的所有终止状态。 - Andre Holzner