我正在处理一个多类别分类问题,目标列有五个类别。我已经使用扩展平均编码(Target encoding)为分类变量生成了特征。该方法基于将分类变量值编码为每个值的目标变量平均值。
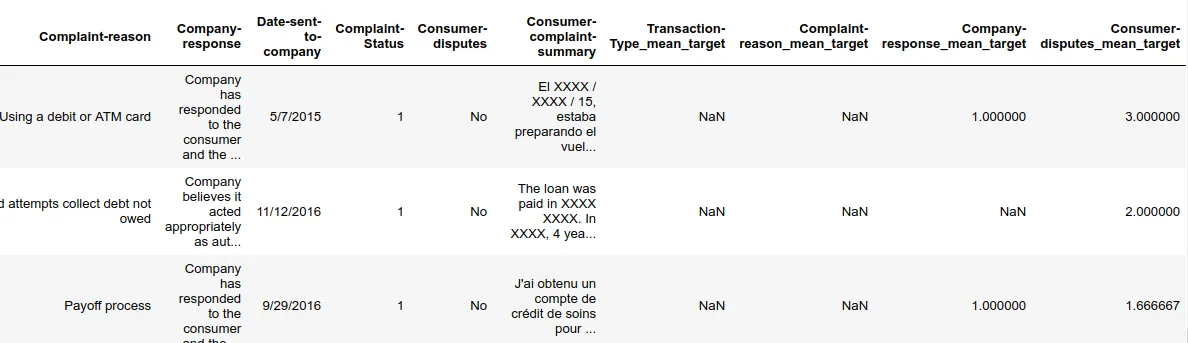
这也会导致一些NaN值,例如“Transaction-Type_mean_target”列。
1. 如何填充这些NaN值?我应该用列平均值来填充吗? 2. 当目标/依赖变量“Complaint-Status”不存在时,如何为我的测试数据生成平均编码?
输入数据:
这也会导致一些NaN值,例如“Transaction-Type_mean_target”列。
1. 如何填充这些NaN值?我应该用列平均值来填充吗? 2. 当目标/依赖变量“Complaint-Status”不存在时,如何为我的测试数据生成平均编码?
输入数据:
def add_feat_mean_encoding(col_list):
"""
Expanding mean encoding
"""
for i in col_list:
cumsum = train.groupby(i)['Complaint-Status'].cumsum() - train['Complaint-Status']
cumcnt = train.groupby(i).cumcount()
train[i+'_mean_target'] = cumsum/cumcnt
cat_var = ['Transaction-Type','Complaint-reason','Company-response','Consumer-disputes']
add_feat_mean_encoding(cat_var)