假设,例如,我有一些包含许多元素的 HTML 代码,看起来像这样。
我需要使用正则表达式在整个文档中仅删除所有
<div id="1-element" class="1-element">...</div>
<div id="2-element" class="2-element">...</div>
...
<div id="99-element" class="99-element">...</div>
<div id="100-element" class="100-element">...</div>
...
我需要使用正则表达式在整个文档中仅删除所有
class="*-element"部分,但保留div、id和其他内容。请问在Notepad++中我该如何实现呢?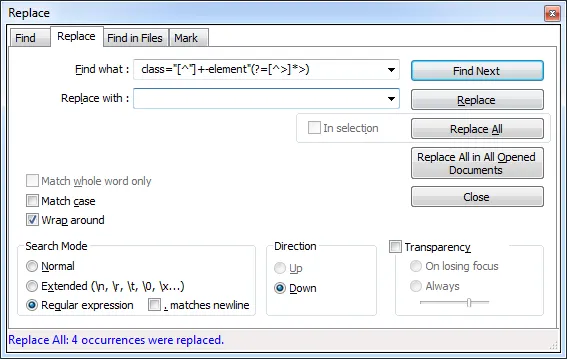
class="element *-element"这样的情况该怎么办? - Vlad Zhukov\bclass="[^"]*element"。 - vks