是的,从几个角度来看,这与其他情况有很大不同。正如你在问题标题中所写的那样,它关于理解为什么我们需要数据卷而不是绑定到主机上。
第一部分 - 基本场景和示例
让我们列举两个场景。
情况1:Web服务器
我们想要为我们的Web服务器提供一个配置文件,该文件可能会经常更改。
例如:根据当前环境暴露端口。
我们可以每次重新构建具有相关设置的映像,或者为每个环境创建2个不同的映像。这两种解决方案都不太有效。
通过绑定挂载点,Docker将给定源目录挂载到容器内部的位置。
(联合文件系统中只读层中的原始目录/文件将被覆盖)。
例如-将动态端口绑定到nginx:
version: "3.7"
services:
web:
image: nginx:alpine
volumes:
- type: bind
source: ./mysite.template
target: /etc/nginx/conf.d/mysite.template
ports:
- "9090:8080"
environment:
- PORT=8080
command: /bin/sh -c "envsubst < /etc/nginx/conf.d/mysite.template >
/etc/nginx/conf.d/default.conf && exec nginx -g 'daemon off;'"
(*) 请注意,本例也可以使用卷来解决。
案例二:数据库
Docker 容器不会存储持久数据-任何写入容器联合文件系统可写层的数据都将在容器停止运行时丢失。
但如果我们在容器上运行数据库,当容器停止时,这意味着所有数据都将丢失?
卷 来挽救。
这些是由 Docker 为我们管理的命名文件系统树。
例如-持续保存 Postgres SQL 数据:
services:
db:
image: postgres:latest
volumes:
- "dbdata:/var/lib/postgresql/data"
volumes:
- type: volume
source: dbdata
target: /var/lib/postgresql/data
volumes:
dbdata:
请注意,在这种情况下,对于命名的卷,源是卷的名称(对于匿名卷,该字段被省略)。
第二部分 - 比较
主机上管理和隔离的差异
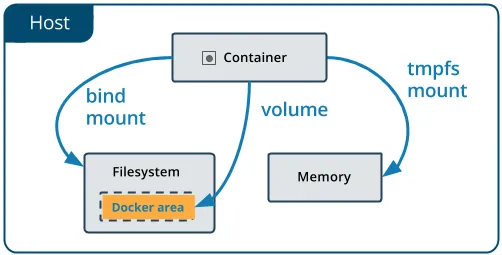
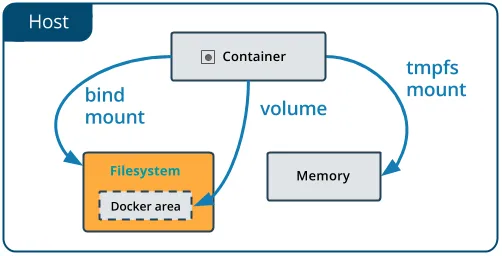
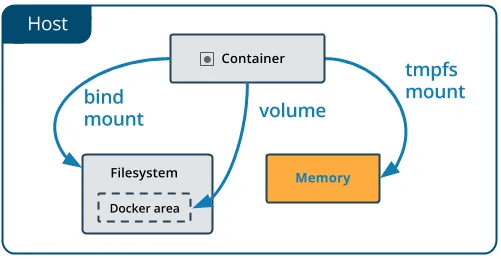
绑定挂载点存在于主机文件系统上并由主机维护者管理。 Docker之外的应用程序/进程也可以修改它。
卷也可以在主机上实现,但Docker会为我们管理它们,并且无法在Docker之外访问。
卷是一个更广泛的解决方案
虽然这两个解决方案都帮助我们将数据生命周期与容器分离,
但使用卷可以使您在系统上获得更多的功能和灵活性。
使用卷,我们可以通过将数据存储在专用远程位置(例如云中)并将其与备份,监视,加密和硬件管理等外部服务集成来有效地设计数据并将其与系统的其他部分解耦。