我已经寻找这个问题的答案有一段时间了,所以我希望有人能帮助我。我正在使用R中fpc库中的dbscan。例如,我正在查看USArrests数据集,并按如下方式使用dbscan:
library(fpc)
ds <- dbscan(USArrests,eps=20)
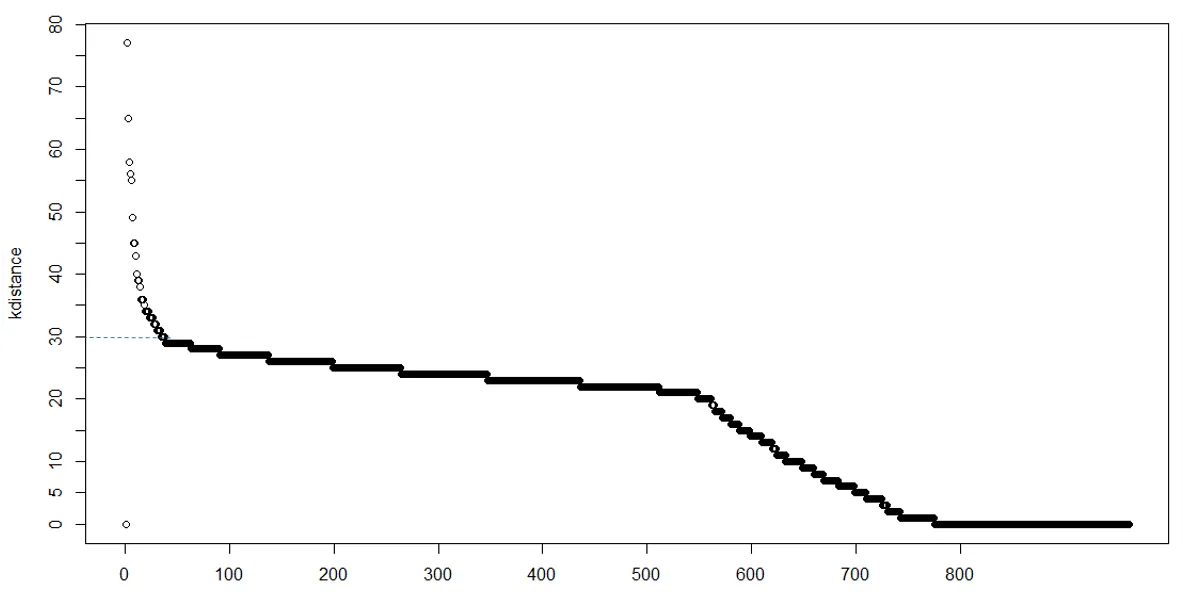
这种类型的图表对于帮助选择适当的eps和minpts值非常有用。我希望我已经提供了足够的信息,以便有人能够帮助我。我想发布一个我所说的图片,但我还是新手,所以现在不能发布图片。
data.frame,可能是R中使用最广泛的数据结构,并不是矩阵而是列表)。出于性能原因,实现时可能会使用Rcpp。 - Ari B. FriedmanfpcDBSCAN 比其他实现方式慢了 10 倍。只有 Weka 更差(慢了另外的 8 倍)。 - Has QUIT--Anony-Mousse