我正在寻找sklearn中的一个模块,可以生成单词共现矩阵。
我可以获取文档-单词矩阵,但不确定如何获取单词共现矩阵。
我正在寻找sklearn中的一个模块,可以生成单词共现矩阵。
我可以获取文档-单词矩阵,但不确定如何获取单词共现矩阵。
以下是使用scikit-learn中的CountVectorizer的示例解决方案。 参考此帖子,您可以仅使用矩阵乘法获得单词共现矩阵。
from sklearn.feature_extraction.text import CountVectorizer
docs = ['this this this book',
'this cat good',
'cat good shit']
count_model = CountVectorizer(ngram_range=(1,1)) # default unigram model
X = count_model.fit_transform(docs)
# X[X > 0] = 1 # run this line if you don't want extra within-text cooccurence (see below)
Xc = (X.T * X) # this is co-occurrence matrix in sparse csr format
Xc.setdiag(0) # sometimes you want to fill same word cooccurence to 0
print(Xc.todense()) # print out matrix in dense format
您还可以参考count_model中的词典。
count_model.vocabulary_
或者,如果您想要通过对角元素进行规范化(参见上一篇帖子的答案)。
import scipy.sparse as sp
Xc = (X.T * X)
g = sp.diags(1./Xc.diagonal())
Xc_norm = g * Xc # normalized co-occurence matrix
额外说明:请注意@Federico Caccia的回答,如果您不想在自己的文本中出现虚假共现,请将大于1的共现设为1。
X[X > 0] = 1 # do this line first before computing cooccurrence
Xc = (X.T * X)
...
所有提供的答案都没有考虑窗口移动的概念。因此,我编写了自己的函数,通过应用定义大小的移动窗口来查找共现矩阵。
此函数接受一个句子列表和一个window_size数字; 并返回表示共现矩阵的pandas.DataFrame对象:
from collections import defaultdict
def co_occurrence(sentences, window_size):
d = defaultdict(int)
vocab = set()
for text in sentences:
# preprocessing (use tokenizer instead)
text = text.lower().split()
# iterate over sentences
for i in range(len(text)):
token = text[i]
vocab.add(token) # add to vocab
next_token = text[i+1 : i+1+window_size]
for t in next_token:
key = tuple( sorted([t, token]) )
d[key] += 1
# formulate the dictionary into dataframe
vocab = sorted(vocab) # sort vocab
df = pd.DataFrame(data=np.zeros((len(vocab), len(vocab)), dtype=np.int16),
index=vocab,
columns=vocab)
for key, value in d.items():
df.at[key[0], key[1]] = value
df.at[key[1], key[0]] = value
return df
让我们来试试以下两个简单句子:
>>> text = ["I go to school every day by bus .",
"i go to theatre every night by bus"]
>>>
>>> df = co_occurrence(text, 2)
>>> df
. bus by day every go i night school theatre to
. 0 1 1 0 0 0 0 0 0 0 0
bus 1 0 2 1 0 0 0 1 0 0 0
by 1 2 0 1 2 0 0 1 0 0 0
day 0 1 1 0 1 0 0 0 1 0 0
every 0 0 2 1 0 0 0 1 1 1 2
go 0 0 0 0 0 0 2 0 1 1 2
i 0 0 0 0 0 2 0 0 0 0 2
night 0 1 1 0 1 0 0 0 0 1 0
school 0 0 0 1 1 1 0 0 0 0 1
theatre 0 0 0 0 1 1 0 1 0 0 1
to 0 0 0 0 2 2 2 0 1 1 0
[11 rows x 11 columns]
from collections import defaultdict。因此,defaultdict(int)是一个具有int值的字典。唯一的区别在于,当未找到键时,defaultdict不会引发KeyError异常。这就是我使用它的原因。 - Anwarvic2的移动窗口,这意味着对于索引为i的每个单词,我只考虑索引为i-1、i-2、i+1和i+2的单词。这就是为什么(to,every)的值为2,而(to,bus)的值为0。希望这可以帮助到你。 - AnwarvicXc = (Y.T * Y) # this is co-occurrence matrix in sparse csr format
在这里,我们使用一个矩阵Y来代替X,矩阵Y中大于0的位置为1,其他位置为0。
使用这个方法,对于第一个例子,我们有: 共现:1*1+1*0+1*0+1*0+1*0=1 而对于第二个例子: 共现:1*1+1*1+1*1+1*1+1*0=5 这正是我们真正想要的结果。
CountVectorizer 或 TfidfVectorizer 中使用 ngram_range 参数。bigram_vectorizer = CountVectorizer(ngram_range=(2, 2)) # by saying 2,2 you are telling you only want pairs of 2 words
vocabulary 参数,例如:vocabulary = {'awesome unicorns':0, 'batman forever':1}
这是一段自解释并可直接使用的代码,其中预定义了词-词共现。在这种情况下,我们正在跟踪 awesome unicorns 和 batman forever 的共现。from sklearn.feature_extraction.text import CountVectorizer
import numpy as np
samples = ['awesome unicorns are awesome','batman forever and ever','I love batman forever']
bigram_vectorizer = CountVectorizer(ngram_range=(1, 2), vocabulary = {'awesome unicorns':0, 'batman forever':1})
co_occurrences = bigram_vectorizer.fit_transform(samples)
print 'Printing sparse matrix:', co_occurrences
print 'Printing dense matrix (cols are vocabulary keys 0-> "awesome unicorns", 1-> "batman forever")', co_occurrences.todense()
sum_occ = np.sum(co_occurrences.todense(),axis=0)
print 'Sum of word-word occurrences:', sum_occ
print 'Pretty printig of co_occurrences count:', zip(bigram_vectorizer.get_feature_names(),np.array(sum_occ)[0].tolist())
('awesome unicorns', 1), ('batman forever', 2),这个结果与我们提供的samples数据完全对应。#https://dev59.com/LG445IYBdhLWcg3wdqOO
import pandas as pd
def co_occurance_matrix(input_text,top_words,window_size):
co_occur = pd.DataFrame(index=top_words, columns=top_words)
for row,nrow in zip(top_words,range(len(top_words))):
for colm,ncolm in zip(top_words,range(len(top_words))):
count = 0
if row == colm:
co_occur.iloc[nrow,ncolm] = count
else:
for single_essay in input_text:
essay_split = single_essay.split(" ")
max_len = len(essay_split)
top_word_index = [index for index, split in enumerate(essay_split) if row in split]
for index in top_word_index:
if index == 0:
count = count + essay_split[:window_size + 1].count(colm)
elif index == (max_len -1):
count = count + essay_split[-(window_size + 1):].count(colm)
else:
count = count + essay_split[index + 1 : (index + window_size + 1)].count(colm)
if index < window_size:
count = count + essay_split[: index].count(colm)
else:
count = count + essay_split[(index - window_size): index].count(colm)
co_occur.iloc[nrow,ncolm] = count
return co_occur
corpus = ['ABC DEF IJK PQR','PQR KLM OPQ','LMN PQR XYZ ABC DEF PQR ABC']
words = ['ABC','PQR','DEF']
window_size =2
result = co_occurance_matrix(corpus,words,window_size)
result
这里是输出结果: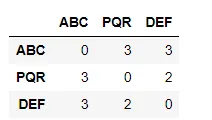
corpus = [['<START>', 'All', 'that', 'glitters', "isn't", 'gold', '<END>'],
['<START>', "All's", 'well', 'that', 'ends', 'well', '<END>']]
和一个单词->行/列映射
def compute_co_occurrence_matrix(corpus, window_size):
words = sorted(list(set([word for words_list in corpus for word in words_list])))
num_words = len(words)
M = np.zeros((num_words, num_words))
word2Ind = dict(zip(words, range(num_words)))
for doc in corpus:
cur_idx = 0
doc_len = len(doc)
while cur_idx < doc_len:
left = max(cur_idx-window_size, 0)
right = min(cur_idx+window_size+1, doc_len)
words_to_add = doc[left:cur_idx] + doc[cur_idx+1:right]
focus_word = doc[cur_idx]
for word in words_to_add:
outside_idx = word2Ind[word]
M[outside_idx, word2Ind[focus_word]] += 1
cur_idx += 1
return M, word2Ind