以下是我的JVM设置:
JAVA_OPTS=-server -Xms2G -Xmx2G -XX:MaxPermSize=512M -Dsun.rmi.dgc.client.gcInterval=1200000 -Dsun.rmi.dgc.server.gcInterval=1200000 -XX:+UseParallelOldGC -XX:ParallelGCThreads=2 -XX:+UseCompressedOops -Djava.net.preferIPv4Stack=true -Djboss.modules.system.pkgs=org.jbos88,server=y,suspend=n
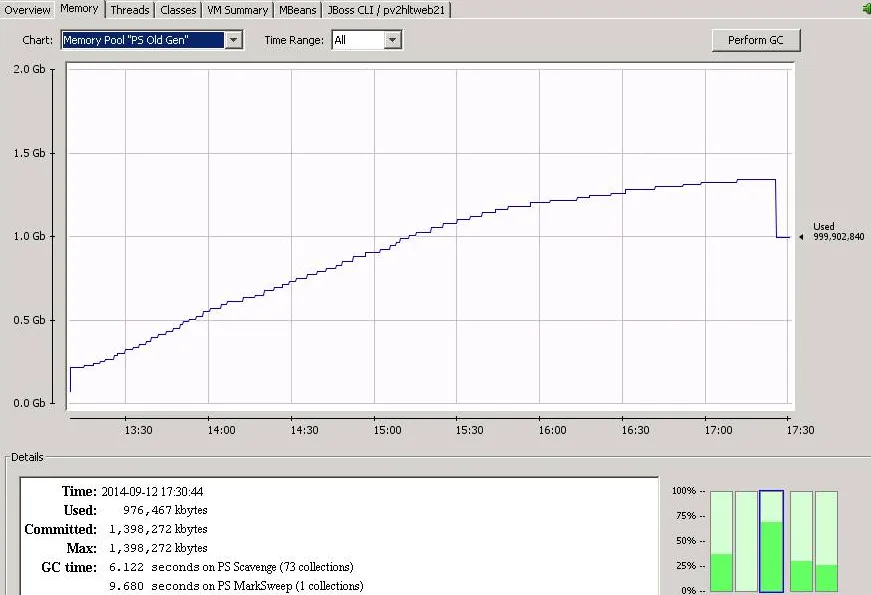
老年代内存超过其分配大小的70%,即使达到100%(即1.4GB),也不被GC处理。如下图所示,它的内存使用率持续高峰,并且从未被GC。在JConsole中强制进行GC时,内存下降。这个问题最终会导致Web服务器崩溃。
我是否错过了什么或错误地设置了JVM?
谢谢提前帮助。
更新我的问题:
堆分析后,看起来有状态会话bean是主要嫌疑人:
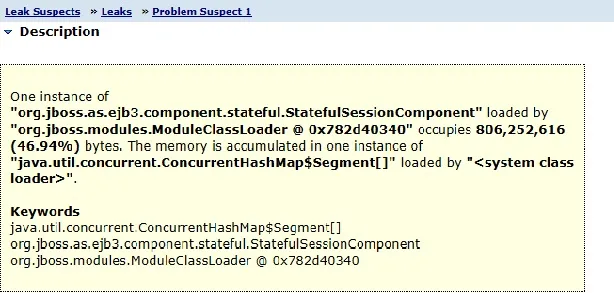 我们有状态会话bean,它们保存由Hibernate辅助的持久性逻辑。
我们有状态会话bean,它们保存由Hibernate辅助的持久性逻辑。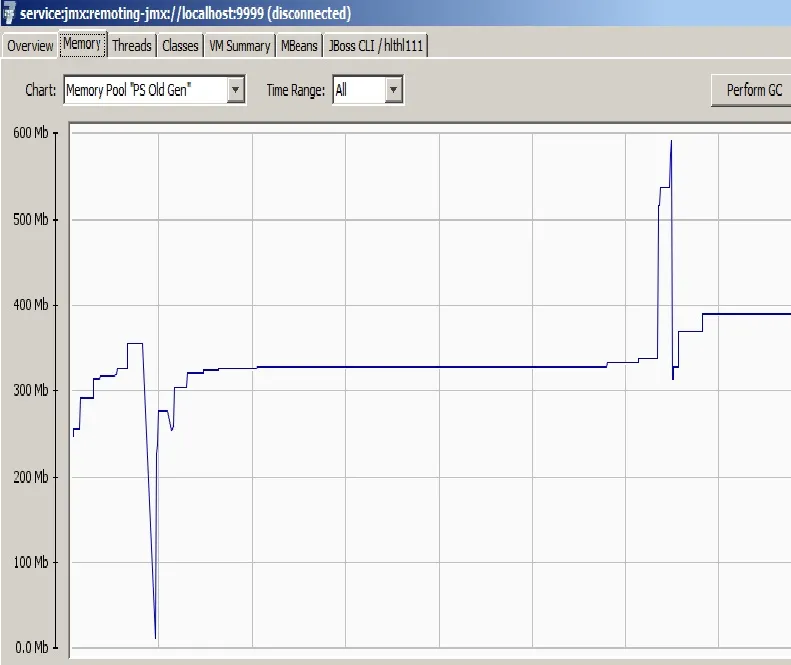 有状态的会话Bean导致JVM内存不足。使用@Remove注释来明确处理它们可以解决这个问题。
有状态的会话Bean导致JVM内存不足。使用@Remove注释来明确处理它们可以解决这个问题。