我有一些使用较旧版本的Python(2.x)编写的代码,现在在Python 3.4中运行时遇到了困难。
_eng_word = ur"[a-zA-Z][a-zA-Z0-9'.]*"
(它是分词器的一部分)
我有一些使用较旧版本的Python(2.x)编写的代码,现在在Python 3.4中运行时遇到了困难。
_eng_word = ur"[a-zA-Z][a-zA-Z0-9'.]*"
(它是分词器的一部分)
http://bugs.python.org/issue15096
标题:停止支持 "ur" 字符串前缀 在 Python 3 中,当 PEP 414 恢复了对明确的 Unicode 文字的支持时,“ur”字符串前缀被视为“r”前缀的同义词。
因此,请使用 'r' 而不是 'ur'
ur'...' 原始字符串字面值的行为。 - Martijn Pieters事实上,Python 3.4仅支持u“...”(为了支持需要在Python 2和3上运行的代码)和r“...”,但不支持两者兼备。这是因为Python 2中ur“...”的语义与Python 3中的ur“...”不同(在Python 2中,\uhhhh和\Uhhhhhhhh转义仍然会被处理,而在Python 3中,r“...”字符串不会)。
请注意,在这个特定情况下,原始字符串字面值和常规字符串没有区别!您可以直接使用:
_eng_word = u"[a-zA-Z][a-zA-Z0-9'.]*"
它可以在Python 2和3中都运行。
对于原始字符串文字确实很重要的情况,您可以将原始字符串从Python 2的raw_unicode_escape进行解码,并在Python 3上捕获AttributeError:
_eng_word = r"[a-zA-Z][a-zA-Z0-9'.]*"
try:
# Python 2
_eng_word = _eng_word.decode('raw_unicode_escape')
except AttributeError:
# Python 3
pass
如果你只写Python 3代码(所以不需要在Python 2上运行),只需完全删除u:
_eng_word = r"[a-zA-Z][a-zA-Z0-9'.]*"
raw_unicode_string编码想法点了赞,但是你的代码在Python 2和Python 3之间会产生不同的结果。 - itsadokunicode_escape:_eng_word ='[a-zA-Z] [a-zA-Z0-9'.]*'; _eng_word.replace(r'\\',r'\\\\')。decode('unicode_escape'),这是 six 使用的方法。 - Martijn Pietersre中,\uhhhh模式也有意义。因此,即使在Python 3中,你最终得到了\\uhhhh(转义)Unicode序列,它们在正则表达式中仍然具有与传递字面Unicode代码点相同的含义。 - Martijn Pieters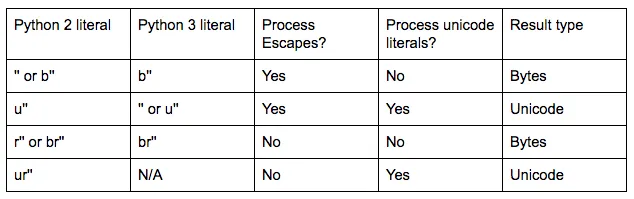 如您所见,在Python 3中,没有办法有一个不处理转义但是处理Unicode字面值的字面量。要在Python 2和3中使用代码获取这样的字符串,请使用:
如您所见,在Python 3中,没有办法有一个不处理转义但是处理Unicode字面值的字面量。要在Python 2和3中使用代码获取这样的字符串,请使用:br"[a-zA-Z][a-zA-Z0-9'.]*".decode('raw_unicode_escape')
实际上,你的例子并不是很好,因为它没有任何Unicode字面量或转义序列。一个更好的例子是:
br"[\u03b1-\u03c9\u0391-\u03a9][\t'.]*".decode('raw_unicode_escape')
在Python 2中:
>>> br"[\u03b1-\u03c9\u0391-\u03a9][\t'.]*".decode('raw_unicode_escape')
u"[\u03b1-\u03c9\u0391-\u03a9][\\t'.]*"
在Python 3中:
>>> br"[\u03b1-\u03c9\u0391-\u03a9][\t'.]*".decode('raw_unicode_escape')
"[α-ωΑ-Ω][\\t'.]*"
这实际上是相同的事情。