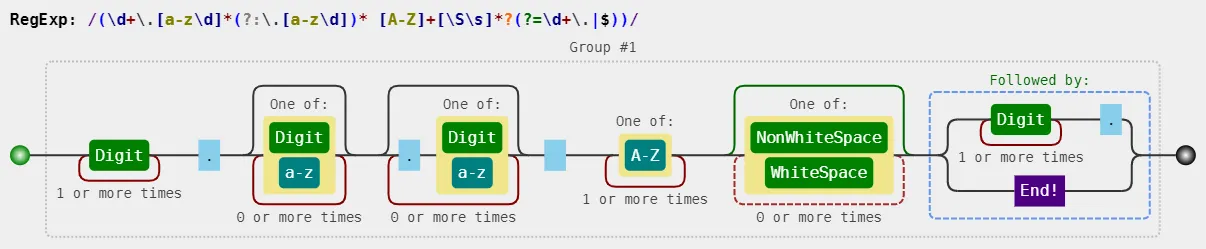
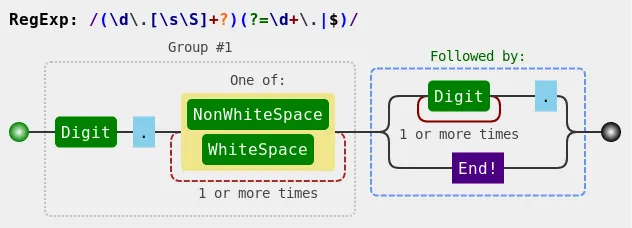
我将尝试从Python字符串中提取匹配的组,但遇到了问题。
字符串如下所示。
并且得到下面的内容。
如果我在正则表达式的末尾添加 .*,匹配组就会受到影响。我觉得我在这里缺少了一些简单的东西。我已经尝试了我所知道的一切,但是无法解决它。任何帮助都将不胜感激。
字符串如下所示。
1. TITLE ABC Contents of title ABC and some other text 2. TITLE BCD This would have contents on
title BCD and maybe something else 3. TITLE CDC Contents of title cdc
我需要提取以数字和大写字母开头的内容作为标题,并提取该标题中的内容。
这是我期望的输出。
1. TITLE ABC Contents of title ABC and some other text
2. TITLE BCD This would have contents on title BCD and maybe something else
3. TITLE CDC Contents of title cdc
我尝试使用以下正则表达式
(\d\.\s[A-Z\s]*\s)
并且得到下面的内容。
1. TITLE ABC
2. TITLE BCD
3. TITLE CDC
如果我在正则表达式的末尾添加 .*,匹配组就会受到影响。我觉得我在这里缺少了一些简单的东西。我已经尝试了我所知道的一切,但是无法解决它。任何帮助都将不胜感激。