我正在寻找一个 JavaScript 函数,可以比较两个字符串并返回它们相似的可能性。我已经查看了 Soundex,但对于多词字符串或非名称并不是很好。我正在寻找像这样的函数:
function compare(strA,strB){
}
compare("Apples","apple") = Some X Percentage.
这个函数可以处理所有类型的字符串,包括数字、多词值和名称。也许有一个简单的算法可以使用?
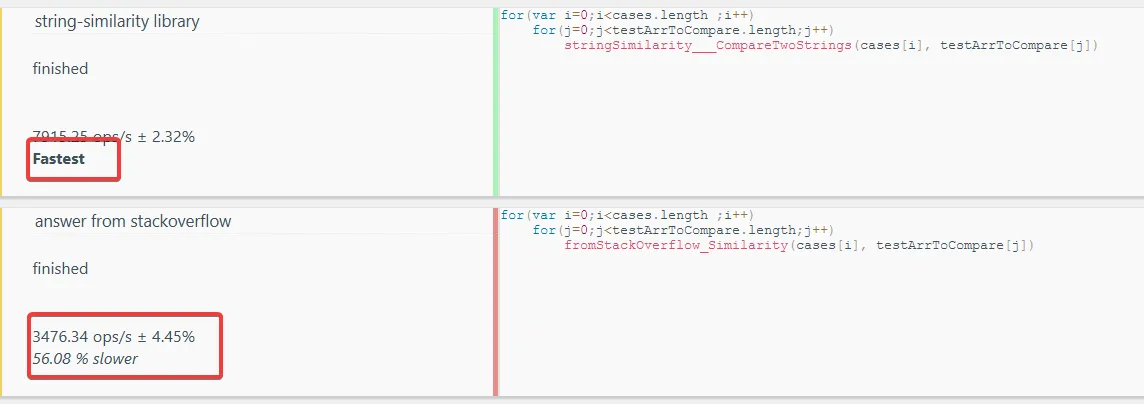
最终,这些都不适合我的目的,所以我使用了这个:
function compare(c, u) {
var incept = false;
var ca = c.split(",");
u = clean(u);
//ca = correct answer array (Collection of all correct answer)
//caa = a single correct answer word array (collection of words of a single correct answer)
//u = array of user answer words cleaned using custom clean function
for (var z = 0; z < ca.length; z++) {
caa = $.trim(ca[z]).split(" ");
var pc = 0;
for (var x = 0; x < caa.length; x++) {
for (var y = 0; y < u.length; y++) {
if (soundex(u[y]) != null && soundex(caa[x]) != null) {
if (soundex(u[y]) == soundex(caa[x])) {
pc = pc + 1;
}
}
else {
if (u[y].indexOf(caa[x]) > -1) {
pc = pc + 1;
}
}
}
}
if ((pc / caa.length) > 0.5) {
return true;
}
}
return false;
}
// create object listing the SOUNDEX values for each letter
// -1 indicates that the letter is not coded, but is used for coding
// 0 indicates that the letter is omitted for modern census archives
// but acts like -1 for older census archives
// 1 is for BFPV
// 2 is for CGJKQSXZ
// 3 is for DT
// 4 is for L
// 5 is for MN my home state
// 6 is for R
function makesoundex() {
this.a = -1
this.b = 1
this.c = 2
this.d = 3
this.e = -1
this.f = 1
this.g = 2
this.h = 0
this.i = -1
this.j = 2
this.k = 2
this.l = 4
this.m = 5
this.n = 5
this.o = -1
this.p = 1
this.q = 2
this.r = 6
this.s = 2
this.t = 3
this.u = -1
this.v = 1
this.w = 0
this.x = 2
this.y = -1
this.z = 2
}
var sndx = new makesoundex()
// check to see that the input is valid
function isSurname(name) {
if (name == "" || name == null) {
return false
} else {
for (var i = 0; i < name.length; i++) {
var letter = name.charAt(i)
if (!(letter >= 'a' && letter <= 'z' || letter >= 'A' && letter <= 'Z')) {
return false
}
}
}
return true
}
// Collapse out directly adjacent sounds
// 1. Assume that surname.length>=1
// 2. Assume that surname contains only lowercase letters
function collapse(surname) {
if (surname.length == 1) {
return surname
}
var right = collapse(surname.substring(1, surname.length))
if (sndx[surname.charAt(0)] == sndx[right.charAt(0)]) {
return surname.charAt(0) + right.substring(1, right.length)
}
return surname.charAt(0) + right
}
// Collapse out directly adjacent sounds using the new National Archives method
// 1. Assume that surname.length>=1
// 2. Assume that surname contains only lowercase letters
// 3. H and W are completely ignored
function omit(surname) {
if (surname.length == 1) {
return surname
}
var right = omit(surname.substring(1, surname.length))
if (!sndx[right.charAt(0)]) {
return surname.charAt(0) + right.substring(1, right.length)
}
return surname.charAt(0) + right
}
// Output the coded sequence
function output_sequence(seq) {
var output = seq.charAt(0).toUpperCase() // Retain first letter
output += "-" // Separate letter with a dash
var stage2 = seq.substring(1, seq.length)
var count = 0
for (var i = 0; i < stage2.length && count < 3; i++) {
if (sndx[stage2.charAt(i)] > 0) {
output += sndx[stage2.charAt(i)]
count++
}
}
for (; count < 3; count++) {
output += "0"
}
return output
}
// Compute the SOUNDEX code for the surname
function soundex(value) {
if (!isSurname(value)) {
return null
}
var stage1 = collapse(value.toLowerCase())
//form.result.value=output_sequence(stage1);
var stage1 = omit(value.toLowerCase())
var stage2 = collapse(stage1)
return output_sequence(stage2);
}
function clean(u) {
var u = u.replace(/\,/g, "");
u = u.toLowerCase().split(" ");
var cw = ["ARRAY OF WORDS TO BE EXCLUDED FROM COMPARISON"];
var n = [];
for (var y = 0; y < u.length; y++) {
var test = false;
for (var z = 0; z < cw.length; z++) {
if (u[y] != "" && u[y] != cw[z]) {
test = true;
break;
}
}
if (test) {
//Don't use & or $ in comparison
var val = u[y].replace("$", "").replace("&", "");
n.push(val);
}
}
return n;
}