我正在学习在stm32F411RE板上(Cortex-M4)使用RTOS。我使用MDK uVision v5。我遇到了一个C代码while循环的问题。以下代码与我的项目和教师的项目(在Udemy上)完全相同,但是,在编译两个项目后(在我的PC上),汇编代码看起来不同。我想问是什么造成了这种不同。谢谢。
void osSignalWait(int32_t *semaphore)
{
__disable_irq();
while(*semaphore <=0)
{
__disable_irq();
__enable_irq();
}
*semaphore -= 0x01;
__enable_irq();
}
在调试视图中(见图像),如果条件不匹配,则不会加载真实值LDR r1,[r0,#0x00],然后进行比较。相反,它会比较并执行while循环内的命令。
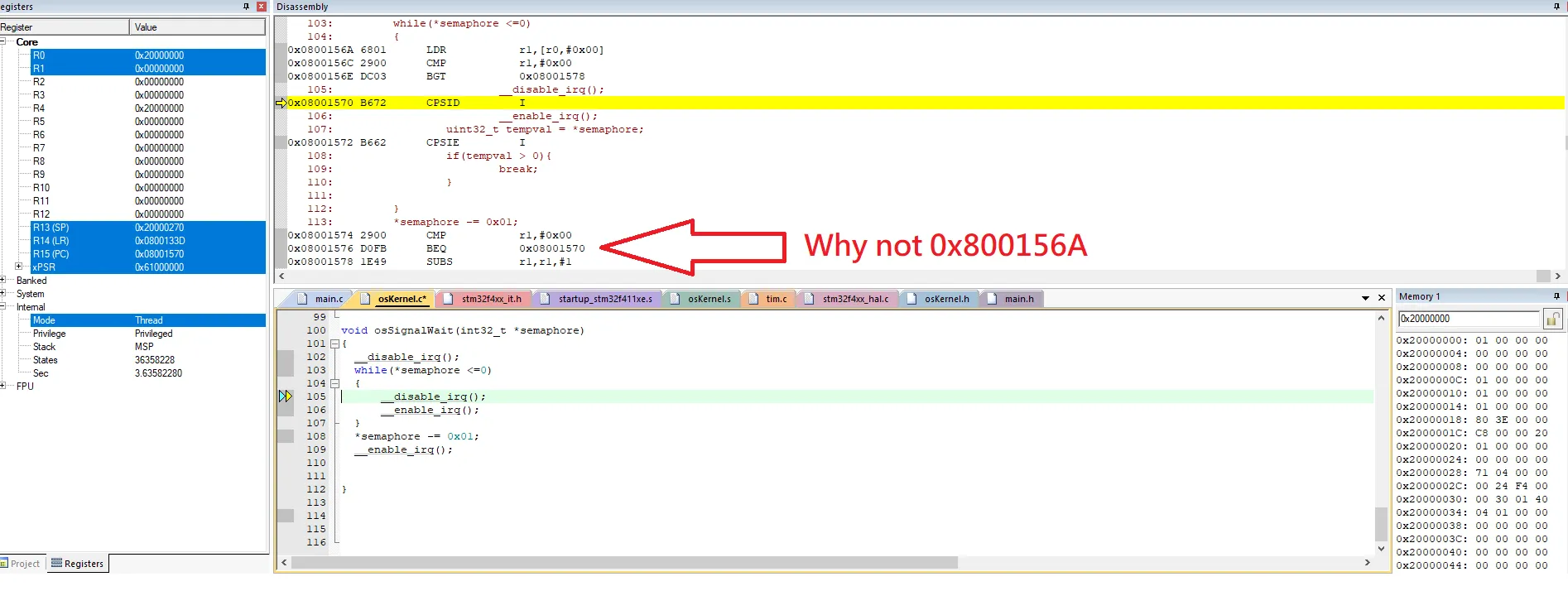 下面是我的已编译代码
下面是我的已编译代码 100: void osSignalWait(int32_t *semaphore)
101: {
0x08001566 4770 BX lr
102: __disable_irq();
103: while(*semaphore <=0)
104: {
0x08001568 B672 CPSID I
101: {
102: __disable_irq();
103: while(*semaphore <=0)
104: {
0x0800156A 6801 LDR r1,[r0,#0x00]
0x0800156C E001 B 0x08001572
105: __disable_irq();
0x0800156E B672 CPSID I
106: __enable_irq();
107: }
108: *semaphore -= 0x01;
0x08001570 B662 CPSIE I
0x08001572 2900 CMP r1,#0x00
0x08001574 DDFB BLE 0x0800156E
0x08001576 1E49 SUBS r1,r1,#1
109: __enable_irq();
0x08001578 6001 STR r1,[r0,#0x00]
0x0800157A B662 CPSIE I
110: }
如果我在我的电脑上使用教练(在Udemy上)的项目编译他的代码,汇编代码看起来会有所不同(但是while循环代码完全相同)。它会重新加载真实值并进行比较。
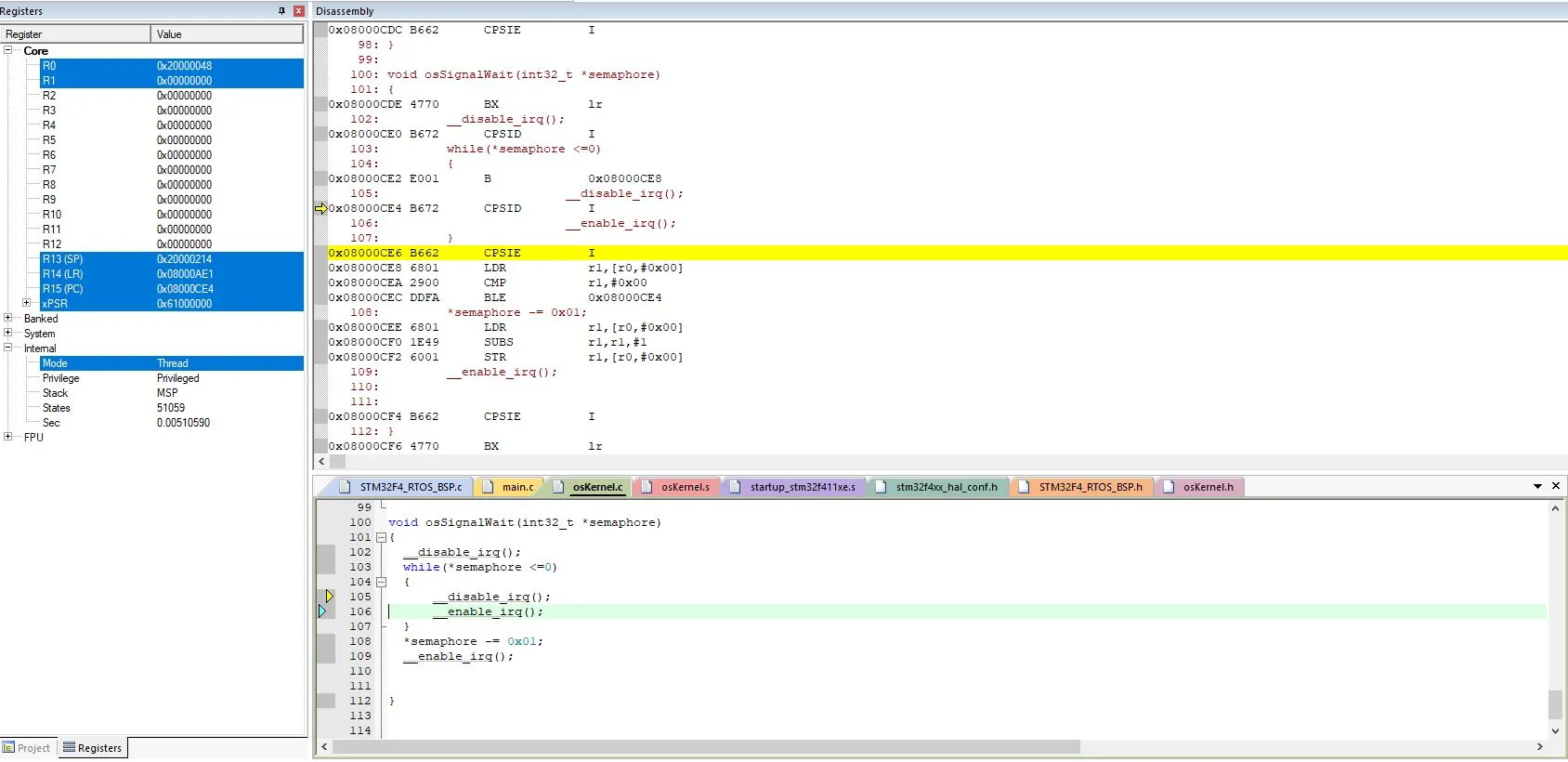 下面是教练的代码编译后的结果(在我的电脑上编译)。
下面是教练的代码编译后的结果(在我的电脑上编译)。100: void osSignalWait(int32_t *semaphore)
101: {
0x08000CDE 4770 BX lr
102: __disable_irq();
0x08000CE0 B672 CPSID I
103: while(*semaphore <=0)
104: {
0x08000CE2 E001 B 0x08000CE8
105: __disable_irq();
0x08000CE4 B672 CPSID I
106: __enable_irq();
107: }
0x08000CE6 B662 CPSIE I
0x08000CE8 6801 LDR r1,[r0,#0x00]
0x08000CEA 2900 CMP r1,#0x00
0x08000CEC DDFA BLE 0x08000CE4
108: *semaphore -= 0x01;
0x08000CEE 6801 LDR r1,[r0,#0x00]
0x08000CF0 1E49 SUBS r1,r1,#1
0x08000CF2 6001 STR r1,[r0,#0x00]
109: __enable_irq();
110:
111:
0x08000CF4 B662 CPSIE I
112: }
__enable_irq(); __disable_irq();的顺序来执行。 - Chris Hall