以下是一种使用递归CTE和分割字符串函数的方法:
;WITH existing_hierachies
AS (SELECT DirID,
BaseDirID,
DisplayPath
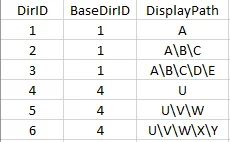
FROM (VALUES (1,1,'A' ),
(2,1,'A\B\C' ),
(3,1,'A\B\C\D\E' ),
(4,4,'U' ),
(5,4,'U\V\W' ),
(6,4,'U\V\W\X\Y' )) tc (DirID, BaseDirID, DisplayPath) ),
folders_list
AS (SELECT ItemNumber,
item fol,
BaseDirID
FROM (SELECT row_number()over(partition by BaseDirID order by Len(DisplayPath) DESC)rn,*
FROM existing_hierachies) a
CROSS apply dbo.[Delimitedsplit8k](DisplayPath, '\')
Where Rn = 1),
rec_cte
AS (SELECT *,
Cast(fol AS VARCHAR(4000))AS hierar
FROM folders_list
WHERE ItemNumber = 1
UNION ALL
SELECT d.*,
Cast(rc.hierar + '\' + d.fol AS VARCHAR(4000))
FROM rec_cte rc
JOIN folders_list d
ON rc.BaseDirID = d.BaseDirID
AND d.ItemNumber = rc.ItemNumber + 1)
SELECT rc.BaseDirID,
rc.hierar AS Missing_Hierarchies
FROM rec_cte rc
WHERE NOT EXISTS (SELECT 1
FROM existing_hierachies eh
WHERE eh.BaseDirID = rc.BaseDirID
AND eh.DisplayPath = rc.hierar)
Order by rc.BaseDirID
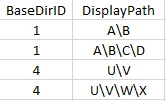
结果:
+
| BaseDirID | Missing_Hierarchies |
+
| 1 | A\B |
| 1 | A\B\C\D |
| 4 | U\V |
| 4 | U\V\W\X |
+
分割字符串函数代码
CREATE FUNCTION [dbo].[DelimitedSplit8K]
(@pString VARCHAR(8000), @pDelimiter CHAR(1))
RETURNS TABLE WITH SCHEMABINDING AS
RETURN
WITH E1(N) AS (
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
cteTally(N) AS (
SELECT TOP (ISNULL(DATALENGTH(@pString),0)) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E4
),
cteStart(N1) AS (
SELECT 1 UNION ALL
SELECT t.N+1 FROM cteTally t WHERE SUBSTRING(@pString,t.N,1) = @pDelimiter
),
cteLen(N1,L1) AS(
SELECT s.N1,
ISNULL(NULLIF(CHARINDEX(@pDelimiter,@pString,s.N1),0)-s.N1,8000)
FROM cteStart s
)
SELECT ItemNumber = ROW_NUMBER() OVER(ORDER BY l.N1),
Item = SUBSTRING(@pString, l.N1, l.L1)
FROM cteLen l
;
GO
引用自http://www.sqlservercentral.com/articles/Tally+Table/72993/
(注:本文主要介绍针对 IT 技术中的 Tally 表的使用,原文详见链接)