Python 3.7引入了dataclasses来存储数据。我正在考虑采用这种新的方法,它比字典更有组织和结构。
但我有一个疑问。Python将字典中的键转换为哈希值,这使得查找键和值更快。数据类实现了类似的功能吗?
哪个更快,为什么?
(Note: Retaining all HTML tags as requested)Python 3.7引入了dataclasses来存储数据。我正在考虑采用这种新的方法,它比字典更有组织和结构。
但我有一个疑问。Python将字典中的键转换为哈希值,这使得查找键和值更快。数据类实现了类似的功能吗?
哪个更快,为什么?
(Note: Retaining all HTML tags as requested)实际上,Python中的所有类都在幕后使用字典来存储它们的属性,您可以在此处的文档中阅读到这一点。关于Python类(以及许多其他内容)如何工作的更详细参考资料,您还可以查看有关Python数据模型的文章,特别是有关自定义类的部分。
因此,通常情况下,从字典转移到数据类不应该导致性能损失。但最好使用timeit模块进行确认:
基准测试
# dictionary creation
$ python -m timeit "{'var': 1}"
5000000 loops, best of 5: 52.9 nsec per loop
# dictionary key access
$ python -m timeit -s "d = {'var': 1}" "d['var']"
10000000 loops, best of 5: 20.3 nsec per loop
基本数据类
# dataclass creation
$ python -m timeit -s "from dataclasses import dataclass" -s "@dataclass" -s "class A: var: int" "A(1)"
1000000 loops, best of 5: 288 nsec per loop
# dataclass attribute access
$ python -m timeit -s "from dataclasses import dataclass" -s "@dataclass" -s "class A: var: int" -s "a = A(1)" "a.var"
10000000 loops, best of 5: 25.3 nsec per loop
在这里,我们可以看到使用类确实会有一些额外的开销。对于类的创建来说,它比较慢(大约慢了5倍),但只要您不打算每秒钟创建和丢弃数据类,那么您并不一定需要过于关注它。
属性访问可能是更重要的度量标准,而数据类再次慢一些(大约1.25倍),但这次差距并不大。
如果您认为速度仍然有点慢,您可以通过使用slots来调整您的数据类(或任何类)代替使用字典来存储它们的属性:
带slot的数据类
# dataclass creation
$ python -m timeit -s "from dataclasses import dataclass" -s "@dataclass" -s "class A: __slots__ = ('var',); var: int" "A(1)"
1000000 loops, best of 5: 242 nsec per loop
# dataclass attribute access
$ python -m timeit -s "from dataclasses import dataclass" -s "@dataclass" -s "class A: __slots__ = ('var',); var: int" -s "a = A(1)" "a.var"
10000000 loops, best of 5: 21.7 nsec per loop
通过使用这种模式,我们可以再节省几个纳秒。至少在属性访问方面,与字典相比,不应该再有明显的差异,您可以使用数据类的优点而不会影响速度。
@Arne提供了一个出色的答案,并证明字典确实是两者中更快的。让我补充一些内容:
正如我在这里的评论中提到的,从Python 3.10开始,有@dataclass(slots = True)选项,可以创建具有插槽成员的数据类,与Arne示例中的更快的方法完全相同。除非您知道自己需要它,否则没有什么理由不使用slots = True。
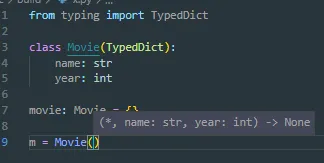
现在转向另一个较少为人知的选择。您可能会选择数据类而不是字典的主要原因之一是为了IDE提示(例如intellisense)和检查所期望的键是否存在。自Python 3.8以来,已经有了PEP589 TypedDict,它允许使用字典的标准格式进行此操作。请考虑以下内容:
from typing import TypedDict
class Movie(TypedDict):
name: str
year: int
movie: Movie = {'name': 'Blade Runner',
'year': 1982}
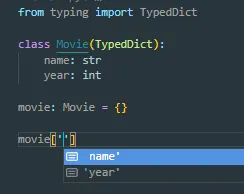
TypedDict可以为您提供一些重要的dataclass优势,而不使用dataclasses。总体而言,在您已经使用字典或仍需要像易于嵌套和略微更好的性能等字典功能时,这是一个很好的解决方案。请参阅上述PEP链接以获取大量良好的示例。attrs或pydantic。 - undefined
@dataclass(slots=True)!这模拟了示例中展示的slotted dataclass的功能。使用python -m timeit -s "from dataclasses import dataclass" -s "@dataclass(slots=True)" -s "class A: var: int" "A(1)"进行创建,使用python -m timeit -s "from dataclasses import dataclass" -s "@dataclass(slots=True)" -s "class A: var: int" -s "a = A(1)" "a.var"进行访问,时间与您的slotted dataclass示例相同。 - Trevor Gross