在Hyperledger Fabric: A Distributed Operating System for Permissioned Blockchains这篇文章中,Hyperledger社区展示了Fabric在某些常见的部署配置下实现了超过3500次每秒的端到端吞吐量。我正在尝试在我的项目中实现这个结果,但我离它还很远。在这里,我报告了我的第一批负载测试结果,并邀请您加入调查,以了解如何使用Hyperledger Fabric和Composer实现高吞吐量。
项目描述
我们构建了一个使用Hyperledger Fabric的高负载服务。我们的后端系统由HF区块链网络、几个微服务(node js)和用于微服务之间通信的消息代理组成,这些微服务通过Hyperledger Composer与区块链进行通信。
Hyperledger Fabric v1.1. Hypeledger Composer v0.19.0
Fabric网络(使用Cello部署):
{
fabric001: {
cas: [],
peers: ["anchor@peer1st.main"],
orderers: ["orderer1st.orderer"],
zookeepers: ["zookeeper1st"],
kafkas: ["kafka1st"]
},
fabric002: {
cas: [],
peers: ["worker@peer2nd.main"],
orderers: ["orderer2nd.orderer"],
zookeepers: ["zookeeper2nd"],
kafkas: ["kafka2nd"]
},
fabric003: {
cas: [],
peers: ["worker@peer3rd.main"],
orderers: ["orderer3rd.orderer"],
zookeepers: ["zookeeper3rd"],
kafkas: ["kafka3rd"]
},
fabric004: {
cas: ["ca1st.main"],
peers: [],
orderers: ["orderer4th.orderer"],
zookeepers: ["zookeeper4th"],
kafkas: ["kafka4th"]
}
}
fabric001-004 - AWS ec2实例的类型为t2.xlarge。最初我使用了m5.4xlarge,但成本很高,即使当Fabric开始出现故障时,CPU使用率仍然很低。
Fabric配置:
BatchTimeout: 0.2s
BatchSize:
MaxMessageCount: 10
AbsoluteMaxBytes: 98 MB
PreferredMaxBytes: 512 KB
TLS已禁用。
如果需要,我可以使用任何配置执行新的测试。
负载测试
首先,我决定测试对账本状态(CouchDB)的请求。区块链是空的,只有系统数据和少数参与者。直接查询 CouchDB 开放端口的请求非常快(约 150 毫秒)。我的微服务通过建立永久连接到现有身份来连接 Fabric。在我们的系统中,请求需要约 500 毫秒,没有高负载情况下,其中一半时间用于消息代理(AWS SQS 真的很慢)。为了进行负载测试,我使用了 YandexTank 工具。在负载增加到每秒约 70 个请求时,负载平稳进行而没有延迟增加。然后延迟统计数据开始下降,并且在某些时候,链码开始返回错误消息。您可以在此处查看测试结果:
在负载测试的迭代过程中,我收到了两种类型的错误消息:
1.
[Hyperledger-Composer] undefined:HLFQueryHandler :queryChaincode() 查询有效载荷返回错误:错误:2 UNKNOWN:执行链码时出错:在执行交易时超时
2.
LFQueryHandler :queryChaincode() 查询有效载荷返回错误:错误:2 UNKNOWN:执行链码时出错:交易返回失败:错误:当前身份为名称为'txBuilder'和标识符 '5606acbada327a8ef33134e601f990076872b31a3dda5ec0a983e04915d16007', 尚未注册
链码容器本身不会重新启动,但是从此时起它的工作情况不佳。有时我无法ping它,有时可以,但无论如何延迟都很大。只有对等方容器的重启才能帮助。(提醒一下,由于Composer,对分类账的请求通过一个对等方进行,这并不好,但这不是我的调查重点)。 第二个错误真的很奇怪,因为这是我使用的唯一身份,而且在链码开始失败之前它是有效的。并且在我重新启动对等方之后它仍然有效。
在应用负载期间,同行、链码和CouchDB的CPU使用率最高(如预期所述)。我正在配置监控系统以监视我的区块链网络,并很快将能够分享更多信息。有什么想法吗?
更新 #1
我被建议使用c*-类型的AWS实例来部署Fabric。我选择了c5.4xlarge(16 vCPU)进行测试。此外,我稍微更改了Fabric配置:
BatchTimeout: 1s
BatchSize:
MaxMessageCount: 20
AbsoluteMaxBytes: 98 MB
PreferredMaxBytes: 512 KB
我进行了相同的测试,但遗憾的是,我得到了相同的结果:
在下图中,您可以看到容器在持续1分钟的测试期间的CPU使用情况图表。
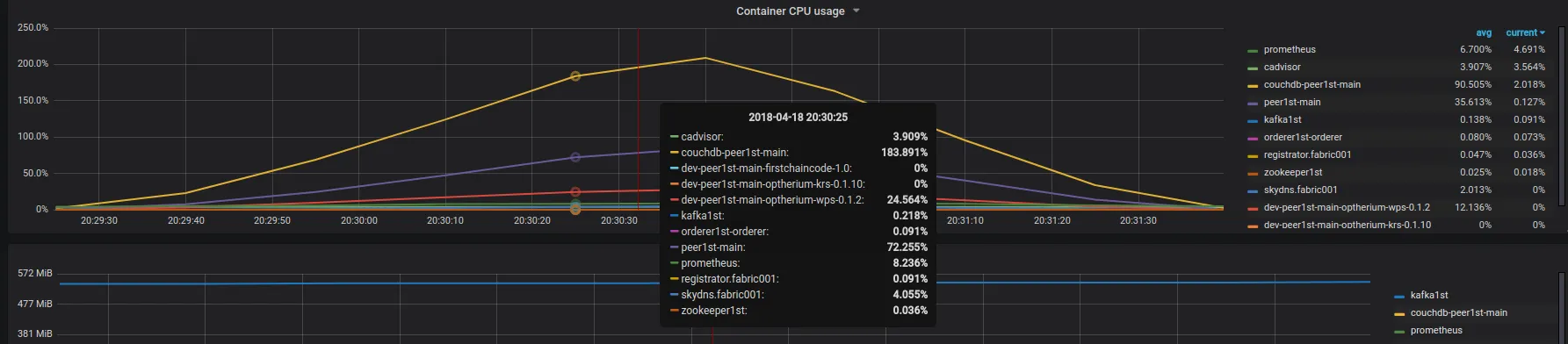
更新 #2
由于性能表现非常糟糕,我决定继续使用纯粹的 Fabric 进行测试,没有任何不必要的中间组件。只有 Fabric 网络和 nodejs SDK。请查看新报告这里