为什么不直接这样做:
data.table(v1 = nVector)[, index := .I][, list(unlist(strsplit(v1, " "))), by = index]
或者,您可以创建一个像以下这样的函数(使用函数更多是为了重复利用的方便性 - 如果只是一次性问题,则不需要):
fun <- function(invec) {
x <- strsplit(invec, " ", TRUE)
data.table(index = rep(seq_along(x), lengths(x)), V1 = unlist(x, use.names = FALSE))
}
fun(nVector)
请注意,使用
fixed = TRUE将为您提供很好的速度提升-因此即使在“data.table”方法中,您也应该考虑这一点。
最后,正如@Jaap所建议的那样,您可以使用我的“splitstackshape”包中的
cSplit,像这样:
library(splitstackshape)
cSplit(data.table(v1 = nVector)[, index := .I], "v1", sep = " ", direction = "long")
更新
由于数据规模较大,性能是一个问题,您可能希望使用手动创建"data.table"的fun方法。
这是一些更大版本向量的时间计算:
NVector <- rep(nVector, 10000)
length(NVector)
f1 <- function(invec) {
data.table(v1 = invec)[, index := .I][
, list(unlist(strsplit(v1, " ", TRUE))), by = index]
}
f2 <- function(invec) {
cSplit(data.table(v1 = invec)[, index := .I],
"v1", sep = " ", direction = "long")
}
library(microbenchmark)
microbenchmark(fun(NVector), f1(NVector), f2(NVector), times = 50)
更新:2017年12月28日
这些方法的性能很可能部分取决于生成的分割片段数量,因此我想:
- 使用一些更不规则的数据更新答案
- 添加几个选项,具体包括:
- 备选的基本R方法
- 使用
stringi替代fun的方法
- 可能的“整洁数据”方法
以下是新的样本数据:
library(stringi)
set.seed(2)
NVec2 <- vapply(sample(20, 60000, TRUE),
function(x) paste(stri_rand_strings(x, 5, "[0-9]"), collapse = " "),
character(1L))
length(NVec2)
以下是新功能:
...
fun_stringi <- function(invec) {
x <- stri_split_fixed(invec, " ")
data.table(index = rep(seq_along(x), lengths(x)), V1 = unlist(x, use.names = FALSE))
}
f3 <- function(invec) stack(setNames(strsplit(invec, " ", TRUE), seq_along(invec)))
f4 <- function(invec) {
data_frame(ind = seq_along(invec),
val = stri_split_fixed(invec, " ")) %>%
unnest()
}
新的基准测试:
library(microbenchmark)
res <- microbenchmark(base = fun(NVec2), stringi = fun_stringi(NVec2),
data_table = f1(NVec2), splitstackshape = f2(NVec2),
base_alt = f3(NVec2), tidyverse = f4(NVec2), times = 50)
res
如果继续增加数据以更接近模拟实际数据集,性能会开始收敛--除了"splitstackshape",它的效率会变得非常慢 :-(
以下是一个示例:
library(stringi)
set.seed(2)
NVec3 <- vapply(sample(100:200, 125000, TRUE),
function(x) paste(stri_rand_strings(x, 5, "[0-9]"), collapse = " "),
character(1L))
system.time({out <- f2(NVec3)})
length(NVec3)
nrow(out)
res <- microbenchmark(base = fun(NVec3), stringi = fun_stringi(NVec3),
data_table = f1(NVec3), base_alt = f3(NVec3),
tidyverse = f4(NVec3), times = 20)
res
autoplot(res, log = FALSE)
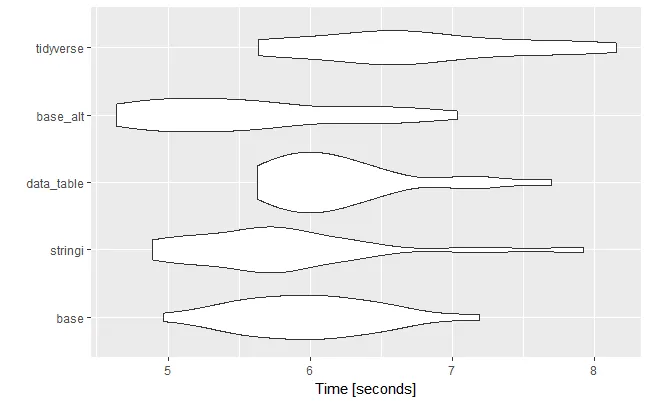
在这一点上,假设你不太可能重复使用此操作,任何选项都应该是相当不错的。我个人很惊讶stack比其他选项表现更好....
data.table解决方案非常好,但是仅供参考,我想指出的是,无论您是否使用data.table,都不需要循环执行此类任务。例如,要创建索引向量,可以执行idx = rep(1:length(nVector), sapply(strsplit(nVector, split=" "), length))。这利用了R中许多函数矢量化的事实,这意味着它们在单个函数调用中对向量的每个元素进行操作。 - eipi10lengths代替sapply(..., length)。快得多.... - A5C1D2H2I1M1N2O1R2T1lengths。 - eipi10