Python的str对象中没有内置的reverse函数。实现此方法的最佳方法是什么?
如果提供非常简洁的答案,请说明其效率。例如,str对象是否转换为不同的对象等。
使用切片:
>>> 'hello world'[::-1]
'dlrow olleh'
切片符号采用 [start:stop:step] 的形式,此时我们省略了 start 和 stop 位置,因为我们想要整个字符串。同时使用 step = -1,意味着“反向每次向左移动一个字符”。
@Paolo的s[::-1]是最快的方法;一个较慢但更易读(也许有争议)的方法是''.join(reversed(s))。
join 必须构建列表才能获取其大小,所以速度较慢。 ''.join(list(reversed(s))) 可能会稍微快一些。 - Jean-François Fabre如何最好地实现字符串翻转函数?
我的经验是学术性的。但如果你是一名专业人士,寻找快速答案,请使用通过-1步进的切片:
>>> 'a string'[::-1]
'gnirts a'
更易读(但由于方法名称查找和join在给定迭代器时形成列表而导致速度较慢),使用str.join:
>>> ''.join(reversed('a string'))
'gnirts a'
或者为了可读性和可重用性,将切片放入一个函数中
def reversed_string(a_string):
return a_string[::-1]
然后:
>>> reversed_string('a_string')
'gnirts_a'
如果您对学术阐述感兴趣,请继续阅读。
Python的str对象中没有内置的反转函数。
下面是关于Python字符串的一些要点:
在Python中,字符串是不可变的。更改字符串不会修改原始字符串,而是创建一个新的字符串。
字符串可以被分片。使用分片符号或一个分片对象将一个字符串从某一点向前或向后按给定增量获取一个新字符串:
string[subscript]
下标可以通过在方括号内使用冒号创建一个切片:
string[start:stop:step]
如果想在大括号外创建一个切片,需要创建一个切片对象:
slice_obj = slice(start, stop, step)
string[slice_obj]
虽然''.join(reversed('foo'))很易读,但它需要在另一个被调用的函数上调用一个字符串方法str.join,这可能相对较慢。让我们把它放在一个函数里 - 我们稍后再回来看:
def reverse_string_readable_answer(string):
return ''.join(reversed(string))
更快的方法是使用反向切片:
'foo'[::-1]
但是,我们如何让不熟悉切片或原始作者意图的人更易读和理解?让我们在下标符号外创建一个切片对象,给它一个描述性名称,并将其传递给下标符号。
start = stop = None
step = -1
reverse_slice = slice(start, stop, step)
'foo'[reverse_slice]
要将其实现为函数,我认为语义上足够清晰,只需使用一个描述性的名称:
def reversed_string(a_string):
return a_string[::-1]
使用方法非常简单:
reversed_string('foo')
如果你有教练,那么他们可能希望你从一个空字符串开始,并从旧字符串中构建一个新字符串。你可以使用 while 循环和纯语法和字面量来做到这一点:
def reverse_a_string_slowly(a_string):
new_string = ''
index = len(a_string)
while index:
index -= 1 # index = index - 1
new_string += a_string[index] # new_string = new_string + character
return new_string
理论上这是不好的,因为记住字符串是不可变的 - 所以每次在new_string上追加字符时,理论上都会创建一个新的字符串!然而,在某些情况下,CPython知道如何优化此过程,其中这个简单的案例就是其中之一。
理论上更好的方法是将子字符串收集到列表中,稍后再将它们连接:
def reverse_a_string_more_slowly(a_string):
new_strings = []
index = len(a_string)
while index:
index -= 1
new_strings.append(a_string[index])
return ''.join(new_strings)
然而,正如我们将在下面看到的CPython时间测试中,这实际上需要更长的时间,因为CPython可以优化字符串拼接。
以下是时间测试结果:
>>> a_string = 'amanaplanacanalpanama' * 10
>>> min(timeit.repeat(lambda: reverse_string_readable_answer(a_string)))
10.38789987564087
>>> min(timeit.repeat(lambda: reversed_string(a_string)))
0.6622700691223145
>>> min(timeit.repeat(lambda: reverse_a_string_slowly(a_string)))
25.756799936294556
>>> min(timeit.repeat(lambda: reverse_a_string_more_slowly(a_string)))
38.73570013046265
CPython会对字符串拼接进行优化,但其他实现可能不会:
不要依赖CPython中针对形如 a += b 或 a = a + b 的语句的原地字符串拼接的高效实现。即使在CPython中,这种优化也是脆弱的(它只适用于某些类型),并且在不使用引用计数的实现中根本不存在。 在库的性能敏感部分应使用“''.join()”形式,这将确保拼接在各种实现中都以线性时间发生。
while循环和减少索引的最佳实践部分,尽管这可能不够易读:for i in range(len(a_string)-1, -1, -1):。最重要的是,我喜欢您选择的示例字符串是您永远不需要反转它的一种情况,并且如果您反转了它,就无法区分:) - Davos这个答案有点长,包含3个部分:现有方案的基准测试,为什么大多数答案是错误的,我的解决方案。
如果忽略Unicode修饰符/字形簇,则现有的答案才是正确的。我稍后会处理这个问题,但首先看一下一些反转算法的速度:
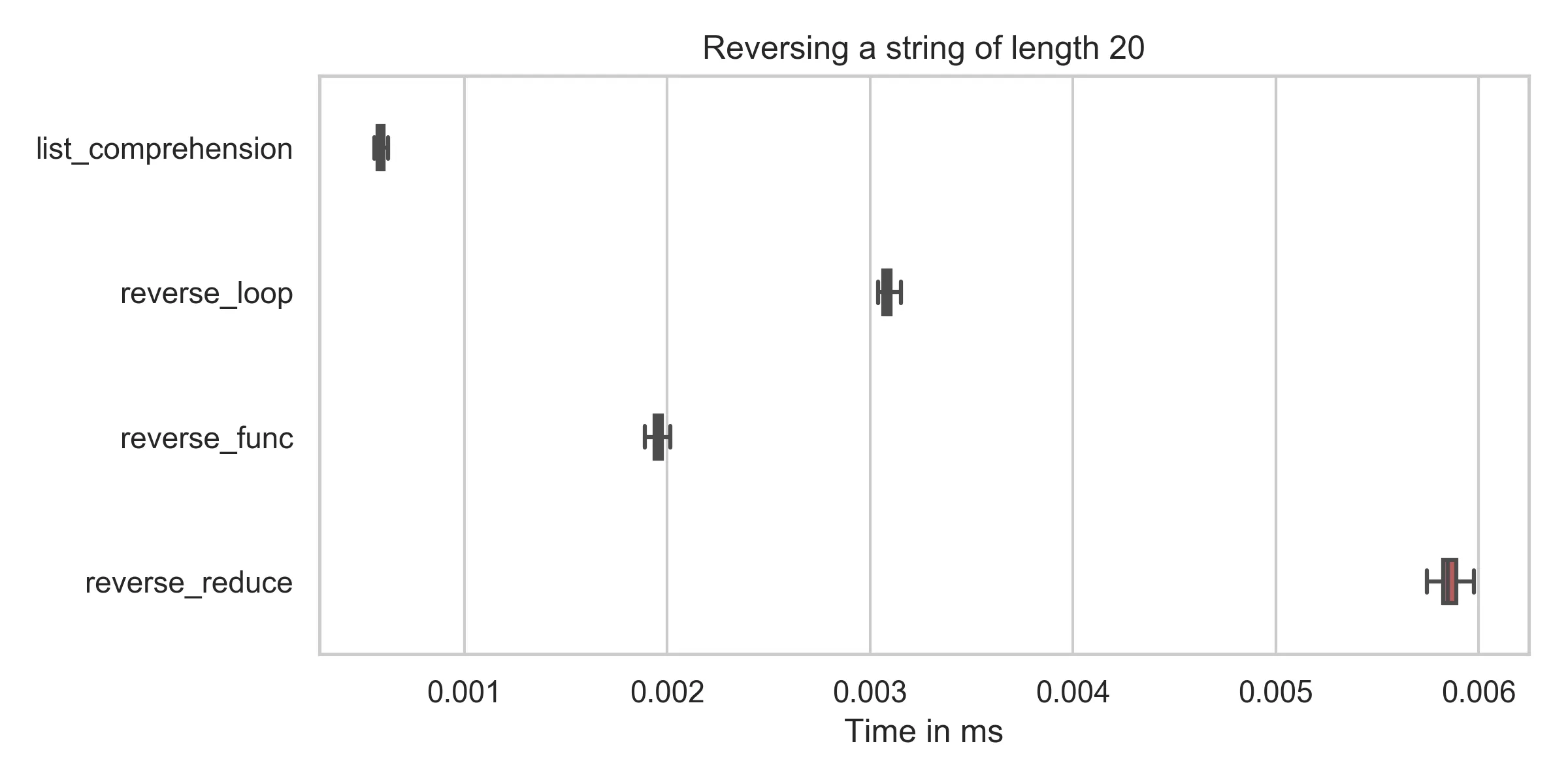
注意:我所谓的list_comprehension应该被称为slicing
slicing : min: 0.6μs, mean: 0.6μs, max: 2.2μs
reverse_func : min: 1.9μs, mean: 2.0μs, max: 7.9μs
reverse_reduce : min: 5.7μs, mean: 5.9μs, max: 10.2μs
reverse_loop : min: 3.0μs, mean: 3.1μs, max: 6.8μs
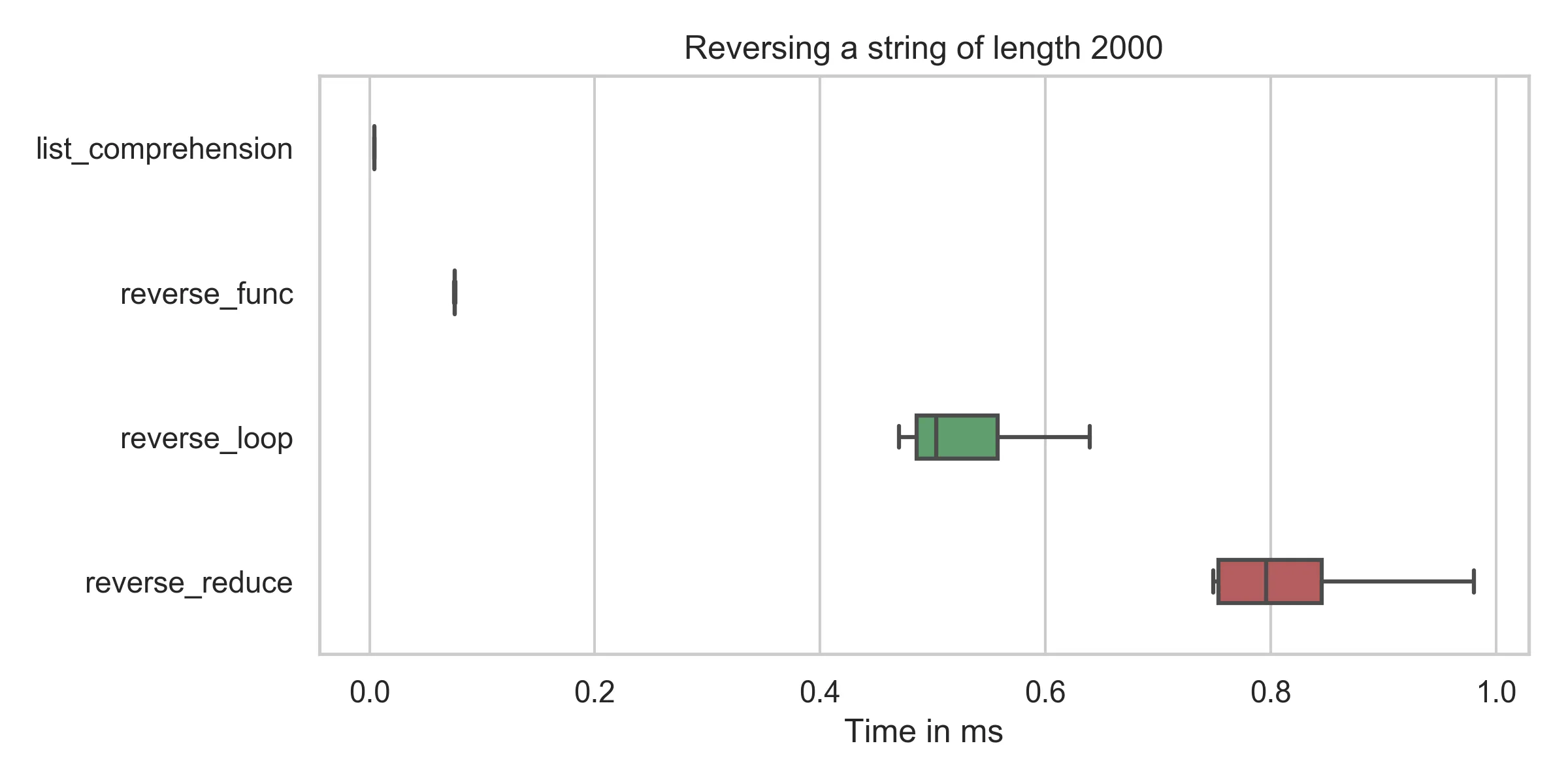
slicing : min: 4.2μs, mean: 4.5μs, max: 31.7μs
reverse_func : min: 75.4μs, mean: 76.6μs, max: 109.5μs
reverse_reduce : min: 749.2μs, mean: 882.4μs, max: 2310.4μs
reverse_loop : min: 469.7μs, mean: 577.2μs, max: 1227.6μs
您可以看到,切片操作的时间 (reversed = string[::-1]) 在所有情况下都远远低于其他方法(即使在修复我的拼写错误后)。
如果您真的想按通常意义上的方式反转一个字符串,那么它会变得更加复杂。例如,取以下字符串(向左指的棕色手指, 向上指的黄色手指)。这是两个字形,但有3个Unicode代码点。额外的一个是肤色修饰符。
example = ""
但是,如果您使用任何给定的方法将其反转,您会得到棕色手指向上, 黄色手指向左。原因是“棕色”颜色修饰符仍然在中间,并应用于其前面的任何内容。所以我们有
和
original: LMU
reversed: UML (above solutions) ☝
reversed: ULM (correct reversal)
Unicode 字符簇 比修饰符代码点要复杂一些。幸运的是,有一个处理 字符 的库:
>>> import grapheme
>>> g = grapheme.graphemes("")
>>> list(g)
['', '']
因此正确的答案是
def reverse_graphemes(string):
g = list(grapheme.graphemes(string))
return ''.join(g[::-1])
这也是迄今为止最慢的:
slicing : min: 0.5μs, mean: 0.5μs, max: 2.1μs
reverse_func : min: 68.9μs, mean: 70.3μs, max: 111.4μs
reverse_reduce : min: 742.7μs, mean: 810.1μs, max: 1821.9μs
reverse_loop : min: 513.7μs, mean: 552.6μs, max: 1125.8μs
reverse_graphemes : min: 3882.4μs, mean: 4130.9μs, max: 6416.2μs
#!/usr/bin/env python3
import numpy as np
import random
import timeit
from functools import reduce
random.seed(0)
def main():
longstring = ''.join(random.choices("ABCDEFGHIJKLM", k=2000))
functions = [(slicing, 'slicing', longstring),
(reverse_func, 'reverse_func', longstring),
(reverse_reduce, 'reverse_reduce', longstring),
(reverse_loop, 'reverse_loop', longstring)
]
duration_list = {}
for func, name, params in functions:
durations = timeit.repeat(lambda: func(params), repeat=100, number=3)
duration_list[name] = list(np.array(durations) * 1000)
print('{func:<20}: '
'min: {min:5.1f}μs, mean: {mean:5.1f}μs, max: {max:6.1f}μs'
.format(func=name,
min=min(durations) * 10**6,
mean=np.mean(durations) * 10**6,
max=max(durations) * 10**6,
))
create_boxplot('Reversing a string of length {}'.format(len(longstring)),
duration_list)
def slicing(string):
return string[::-1]
def reverse_func(string):
return ''.join(reversed(string))
def reverse_reduce(string):
return reduce(lambda x, y: y + x, string)
def reverse_loop(string):
reversed_str = ""
for i in string:
reversed_str = i + reversed_str
return reversed_str
def create_boxplot(title, duration_list, showfliers=False):
import seaborn as sns
import matplotlib.pyplot as plt
import operator
plt.figure(num=None, figsize=(8, 4), dpi=300,
facecolor='w', edgecolor='k')
sns.set(style="whitegrid")
sorted_keys, sorted_vals = zip(*sorted(duration_list.items(),
key=operator.itemgetter(1)))
flierprops = dict(markerfacecolor='0.75', markersize=1,
linestyle='none')
ax = sns.boxplot(data=sorted_vals, width=.3, orient='h',
flierprops=flierprops,
showfliers=showfliers)
ax.set(xlabel="Time in ms", ylabel="")
plt.yticks(plt.yticks()[0], sorted_keys)
ax.set_title(title)
plt.tight_layout()
plt.savefig("output-string.png")
if __name__ == '__main__':
main()
### example01 -------------------
mystring = 'coup_ate_grouping'
backwards = mystring[::-1]
print(backwards)
### ... or even ...
mystring = 'coup_ate_grouping'[::-1]
print(mystring)
### result01 -------------------
'''
gnipuorg_eta_puoc
'''
本答案旨在回应@odigity的以下关注:
哇。一开始我对Paolo提出的解决方案感到恐惧,但是当我读到第一个评论时,我感到的恐惧超过了使用如此基本的加密方法的如此明亮的社区认为这是一个好主意。为什么不只是s.reverse()?
string.reverse() 的功能。string.reverse() 以避免使用切片符号。print 'coup_ate_grouping'[-4:] ## => 'ping'print 'coup_ate_grouping'[-4:-1] ## => 'pin'print 'coup_ate_grouping'[-1] ## => 'g'[-1] 进行索引的不同结果可能会使一些开发人员感到困惑Python有一个特殊情况需要注意:字符串是一种可迭代类型。
不提供string.reverse()方法的理由之一是为了让Python开发人员利用这种特殊情况的优势。
简单来说,这意味着字符串中的每个字符都可以像其他编程语言中的数组元素一样轻松操作,作为顺序排列的元素的一部分。
要了解这是如何工作的,可以查看example02以获得一个很好的概述。
### example02 -------------------
## start (with positive integers)
print 'coup_ate_grouping'[0] ## => 'c'
print 'coup_ate_grouping'[1] ## => 'o'
print 'coup_ate_grouping'[2] ## => 'u'
## start (with negative integers)
print 'coup_ate_grouping'[-1] ## => 'g'
print 'coup_ate_grouping'[-2] ## => 'n'
print 'coup_ate_grouping'[-3] ## => 'i'
## start:end
print 'coup_ate_grouping'[0:4] ## => 'coup'
print 'coup_ate_grouping'[4:8] ## => '_ate'
print 'coup_ate_grouping'[8:12] ## => '_gro'
## start:end
print 'coup_ate_grouping'[-4:] ## => 'ping' (counter-intuitive)
print 'coup_ate_grouping'[-4:-1] ## => 'pin'
print 'coup_ate_grouping'[-4:-2] ## => 'pi'
print 'coup_ate_grouping'[-4:-3] ## => 'p'
print 'coup_ate_grouping'[-4:-4] ## => ''
print 'coup_ate_grouping'[0:-1] ## => 'coup_ate_groupin'
print 'coup_ate_grouping'[0:] ## => 'coup_ate_grouping' (counter-intuitive)
## start:end:step (or start:end:stride)
print 'coup_ate_grouping'[-1::1] ## => 'g'
print 'coup_ate_grouping'[-1::-1] ## => 'gnipuorg_eta_puoc'
## combinations
print 'coup_ate_grouping'[-1::-1][-4:] ## => 'puoc'
了解Python中切片符号的工作原理所需的认知负荷可能对于一些不愿意花费太多时间学习该语言的采用者和开发人员来说确实太多。
然而,一旦掌握了基本原则,这种方法比固定字符串操作方法更具优势。
对于那些持不同看法的人,有替代方案,例如lambda函数、迭代器或简单的一次性函数声明。
如果需要,开发人员可以实现自己的string.reverse()方法,但了解Python背后的原理是很好的。
def rev_string(s):
return s[::-1]
def rev_string(s):
return ''.join(reversed(s))
def rev_string(s):
if len(s) == 1:
return s
return s[-1] + rev_string(s[:-1])
RecursionError: maximum recursion depth exceeded while calling a Python object。例如:rev_string("abcdef"*1000)。 - Adam Parkinstring = 'happy'
print(string)
'开心'
string_reversed = string[-1::-1]
print(string_reversed)
'yppah'
在英文中[-1::-1]的意思是:
“从-1开始,一直到最后,每次步长为-1”
-1 仍然不需要。 - Eric Duminil如何在Python中不使用reversed()或[::-1]来翻转一个字符串
def reverse(test):
n = len(test)
x=""
for i in range(n-1,-1,-1):
x += test[i]
return x
def reverse_words_1(s):
rev = ''
for i in range(len(s)):
j = ~i # equivalent to j = -(i + 1)
rev += s[j]
return rev
def reverse_words_2(s):
rev = ''
for i in reversed(range(len(s)):
rev += s[i]
return rev
另一种更加“异国情调”的方法是使用bytearray,它支持 .reverse() 方法。
b = bytearray('Reverse this!', 'UTF-8')
b.reverse()
b.decode('UTF-8')`
将会产生:
'!siht esreveR'
def reverse(input):
return reduce(lambda x,y : y+x, input)
""[::-1]的结果是""。正确的解决方案是reversed_string = "".join(list(grapheme.graphemes(input_string))[::-1])。请参见下面的Martin的回答。 - amaurea