有一种趋势是不鼓励在Python 2中设置sys.setdefaultencoding('utf-8')。有人能列举一些实际问题的真实示例吗?像“它有害”或“它隐藏了错误”这样的论点听起来不太令人信服。
更新:请注意,此问题仅涉及utf-8,而不是“一般情况下”更改默认编码。
如果可以,请提供一些带有代码的示例。
有一种趋势是不鼓励在Python 2中设置sys.setdefaultencoding('utf-8')。有人能列举一些实际问题的真实示例吗?像“它有害”或“它隐藏了错误”这样的论点听起来不太令人信服。
更新:请注意,此问题仅涉及utf-8,而不是“一般情况下”更改默认编码。
如果可以,请提供一些带有代码的示例。
原帖要求展示代码以证明开关是有害的——但除了与开关无关的错误会被“隐藏”之外。
[2020-11-01]: pip install setdefaultencoding
消除了需要从Thomas
Grainger重新加载sys的需求。
[2019]: 个人使用python3的经验:
.encode('utf-8')和.decode('utf-8')。len()函数一样返回用于存储和转发机器的字节数,而不是返回人类的字符数,那么这种方法可能更实用。(来自2017年)
基于我的经验和收集到的证据,我得出了以下结论。
将默认编码设置为UTF-8现在是安全的,除了处理来自非unicode准备系统的文件的专业应用程序。
"官方"拒绝转换的理由对于绝大多数最终用户(而不是库提供者)已经不再相关,因此我们应该停止阻止用户进行设置。
在默认情况下正确处理Unicode的模型比手动使用Unicode API更适合于应用程序进行系统间通信。
实际上,经常修改默认编码可以避免在绝大多数情况下出现用户困扰。是的,有时处理多个编码的程序会默默地出现错误,但由于这个开关可以逐步启用,所以这不是最终用户代码中的问题。
更重要的是,启用此标志对用户代码来说是一个真正的优势,既可以减少手动处理Unicode转换、混乱代码和降低可读性的开销,也可以避免程序员在所有情况下未能正确处理这一问题时可能出现的错误。由于这些说法几乎与Python官方的沟通方式完全相反,我认为有必要对这些结论进行解释。
Dave Malcom of Fedora believed it is always right. He proposed, after investigating risks, to change distribution wide def.enc.=UTF-8 for all Fedora users.
Hard fact presented though why Python would break is only the hashing behavior I listed, which is never picked up by any other opponent within the core community as a reason to worry about or even by the same person, when working on user tickets.
Resume of Fedora: Admittedly, the change itself was described as "wildly unpopular" with the core developers, and it was accused of being inconsistent with previous versions.
There are 3000 projects alone at openhub doing it. They have a slow search frontend, but scanning over it, I estimate 98% are using UTF-8. Nothing found about nasty surprises.
There are 18000(!) github master branches with it changed.
While the change is "unpopular" at the core community its pretty popular in the user base. Though this could be disregarded, since users are known to use hacky solutions, I don't think this is a relevant argument due to my next point.
There are only 150 bugreports total on GitHub due to this. At a rate of effectively 100%, the change seems to be positive, not negative.
To summarize the existing issues people have run into, I've scanned through all of the aforementioned tickets.
Chaging def.enc. to UTF-8 is typically introduced but not removed in the issue closing process, most often as a solution. Some bigger ones excusing it as temporary fix, considering the "bad press" it has, but far more bug reporters are justglad about the fix.
A few (1-5?) projects modified their code doing the type conversions manually so that they did not need to change the default anymore.
In two instances I see someone claiming that with def.enc. set to UTF-8 leads to a complete lack of output entirely, without explaining the test setup. I could not verify the claim, and I tested one and found the opposite to be true.
One claims his "system" might depend on not changing it but we do not learn why.
One (and only one) had a real reason to avoid it: ipython either uses a 3rd party module or the test runner modified their process in an uncontrolled way (it is never disputed that a def.enc. change is advocated by its proponents only at interpreter setup time, i.e. when 'owning' the process).
I found zero indication that the different hashes of 'é' and u'é' causes problems in real-world code.
Python does not "break"
After changing the setting to UTF-8, no feature of Python covered by unit tests is working any differently than without the switch. The switch itself, though, is not tested at all.
It is advised on bugs.python.org to frustrated users
Examples here, here or here (often connected with the official line of warning)
The first one demonstrates how established the switch is in Asia (compare also with the github argument).
Ian Bicking published his support for always enabling this behavior.
I can make my systems and communications consistently UTF-8, things will just get better. I really don't see a downside. But why does Python make it SO DAMN HARD [...] I feel like someone decided they were smarter than me, but I'm not sure I believe them.
Martijn Fassen, while refuting Ian, admitted that ASCII might have been wrong in the first place.
I believe if, say, Python 2.5, shipped with a default encoding of UTF-8, it wouldn't actually break anything. But if I did it for my Python, I'd have problems soon as I gave my code to someone else.
In Python3, they don't "practice what they preach"
While opposing any def.enc. change so harshly because of environment dependent code or implicitness, a discussion here revolves about Python3's problems with its 'unicode sandwich' paradigm and the corresponding required implicit assumptions.
Further they created possibilities to write valid Python3 code like:
>>> from 褐褑褒褓褔褕褖褗褘 import *
>>> def 空手(合氣道): あいき(ど(合氣道))
>>> 空手(う힑힜(' ') + 흾)
DiveIntoPython recommends it.
In this thread, Guido himself advises a professional end user to use a process specific environt with the switch set to "create a custom Python environment for each project."
The fundamental reason the designers of Python's 2.x standard library don't want you to be able to set the default encoding in your app, is that the standard library is written with the assumption that the default encoding is fixed, and no guarantees about the correct workings of the standard library can be made when you change it. There are no tests for this situation. Nobody knows what will fail when. And you (or worse, your users) will come back to us with complaints if the standard library suddenly starts doing things you didn't expect.
Jython offers to change it on the fly, even in modules.
PyPy did not support reload(sys) - but brought it back on user request within a single day without questions asked. Compare with the "you are doing it wrong" attitude of CPython, claiming without proof it is the "root of evil".
def is_clean_ascii(s):
""" [Stupid] type agnostic checker if only ASCII chars are contained in s"""
try:
unicode(str(s))
# we end here also for NON ascii if the def.enc. was changed
return True
except Exception, ex:
return False
if is_clean_ascii(mystr):
<code relying on mystr to be ASCII>
我认为这不是一个有效的论点,因为编写此双类型接受模块的人显然知道ASCII与非ASCII字符串,并且会意识到编码和解码。
我认为这个证据已经足够表明,在现实世界的代码库中,大多数情况下更改此设置不会导致任何问题。
goto。当然,你可以让它工作,但是在开发应用程序时会更加困难。您将无法一致地处理Unicode,这将会对您产生影响。大多数使用它的人不了解Unicode,并认为这是简单的解决方法。 - Martijn Pieterssuper()中看到相同的问题。一般来说,这是一种货物崇拜,应用和误用而不理解它是如何工作的或是否需要。 - Martijn Pieters因为您并不总是希望自动将字符串解码为Unicode,或者说将Unicode对象自动编码为字节。既然您要求一个具体的例子,那么这里有一个:
拿一个WSGI Web应用程序举个例子; 您正在通过在循环中将外部进程的产物添加到列表中来构建响应,并且该外部进程给您提供了UTF-8编码的字节:
results = []
content_length = 0
for somevar in some_iterable:
output = some_process_that_produces_utf8(somevar)
content_length += len(output)
results.append(output)
headers = {
'Content-Length': str(content_length),
'Content-Type': 'text/html; charset=utf8',
}
start_response(200, headers)
return results
这很棒、很好用。但是你的同事会加入一个新功能;你现在还提供标签,并且这些标签是本地化的:
results = []
content_length = 0
for somevar in some_iterable:
label = translations.get_label(somevar)
output = some_process_that_produces_utf8(somevar)
content_length += len(label) + len(output) + 1
results.append(label + '\n')
results.append(output)
headers = {
'Content-Length': str(content_length),
'Content-Type': 'text/html; charset=utf8',
}
start_response(200, headers)
return results
你在英文环境下测试通过了,很棒!
然而, translations.get_label() 库实际上返回的是Unicode值,当你切换语言环境时,标签就会包含非ASCII字符。
WSGI库将这些结果写入套接字,所有的Unicode值都会被自动编码,因为你设置了 setdefaultencoding() 为UTF-8,但是你计算出来的长度完全是错误的。因为UTF-8会用多个字节来编码ASCII范围之外的所有内容。
所有这些都忽略了你可能正在使用不同编解码器的数据;你可能正在编写Latin-1 + Unicode,并且现在你有一个不正确的长度头并且数据编码混乱。
如果你没有使用 sys.setdefaultencoding(),那么就会引发异常,你就知道出现了一个bug,但现在你的客户抱怨响应不完整;页面末尾缺失了一些字节,你不确定发生了什么。
请注意,这种情况甚至不涉及第三方库,这些库可能依赖于默认设置仍然是ASCII。 sys.setdefaultencoding() 设置是全局的,适用于解释器中运行的所有代码。你有多确定没有涉及隐式编码或解码的那些库中存在问题?
当你处理仅涉及ASCII数据时,Python 2会自动将 str 和 unicode 类型之间进行编解码,这可能是有帮助和安全的。但是,当你意外混合使用Unicode和字节字符串数据时,你真的需要知道,而不是用全局方法掩盖它并希望一切顺利。
translations.get_label() 返回 unicode 对象。WSGI 实现也可以选择仅连接所有结果,此时您将获得一个 unicode 对象作为输出传递给套接字,或者可能传递给另一个 WSGI 包装标签。我们不知道,因为我们消除了通常会抛出的所有 Python 异常。 - Martijn Pietersunicode,并尽可能晚地在退出点将其编码为字节。 在这种情况下,我建议阅读/观看Ned Batchelder的Pragmatic Unicode演示文稿。 - Martijn Pieters有 m = {'a': 1, 'é': 2} 和文件 'out.py':
# coding: utf-8
print u'é'
然后:
+---------------+-----------------------+-----------------+
| DEF.ENC | OPERATION | RESULT (printed)|
+---------------+-----------------------+-----------------+
| ANY | u'abc' == 'abc' | True |
| (i.e.Ascii | str(u'abc') | 'abc' |
| or UTF-8) | '%s %s' % ('a', u'a') | u'a a' |
| | python out.py | é |
| | u'a' in m | True |
| | len(u'a'), len(a) | (1, 1) |
| | len(u'é'), len('é') | (1, 2) [*] |
| | u'é' in m | False (!) |
+---------------+-----------------------+-----------------+
| UTF-8 | u'abé' == 'abé' | True [*] |
| | str(u'é') | 'é' |
| | '%s %s' % ('é', u'é') | u'é é' |
| | python out.py | more | 'é' |
+---------------+-----------------------+-----------------+
| Ascii | u'abé' == 'abé' | False, Warning |
| | str(u'é') | Encoding Crash |
| | '%s %s' % ('é', u'é') | Decoding Crash |
| | python out.py | more | Encoding Crash |
+---------------+-----------------------+-----------------+
>>> u1, u2 = open('j1').read(), open('j2').read()
>>> print sys.version.split()[0], u1, u2, u1 == u2
>>> print (sys.version.split()[0], u1, u2, u1 == u2)
('2.7.9', 'Jos\xc3\xa9', 'Jose\xcc\x81', False)
>>> u1, u2 = open('j1').read(), open('j2').read()
>>> print sys.version.split()[0], u1, u2, u1 == u2
实际例子 #1
它在 单元测试 中无法工作。
测试运行器 (nose, py.test, ...) 首先初始化 sys,然后才发现并导入你的模块。到那时,改变默认编码已经太晚了。
同样的,如果有人将你的代码作为模块运行,它也无法工作,因为他们的初始化先进行。
是的,混合使用 str 和 unicode 并仅依赖于隐式转换只会将问题推迟到更后面。
sys.defaultencoding('utf-8') 的主模块,那么为什么它不起作用呢? - anatoly techtoniksys.setdefaultencoding() 不会设置输入或输出编码;我认为你误解了这个函数的作用。它设置了当混合使用 unicode 和 str 类型时,隐式地 将 unicode 编码为 str 或将 str 解码为 unicode 所使用的编解码器。 - Martijn Pieterssys。当你的模块运行时,改变编码已经为时过晚。可用的解决方法是 sitecustomize.py 和 reload(sys)。前者无法与单元测试一起使用,也不可组合。后者是黑魔法,需要自己承担风险。 - Dima Tisnek我们需要知道的一件事是
Python 2使用
sys.getdefaultencoding()在str和unicode之间进行解码/编码。
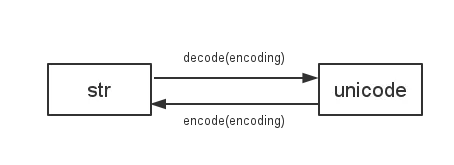
所以如果我们更改默认编码,就会出现各种不兼容问题。例如:
# coding: utf-8
import sys
print "你好" == u"你好"
# False
reload(sys)
sys.setdefaultencoding("utf-8")
print "你好" == u"你好"
# True
更多例子:
说到这里,我记得有一些博客建议尽可能使用Unicode,只有在处理I/O时才使用位串。我认为如果你遵循这个惯例,生活会变得更容易。更多的解决方案可以在以下找到:sys.setdefaultencoding("utf-8")才能使"你好" == u"你好"成立,这是正确的。 - nehem3 == 3.0也是True一样。相等性是关于信息本身的陈述,而不是关于它包装成哪种数据类型的。 - Red Pill>>> print "abc" == u"abc" => True
>>> print "你bc" == u"你bc" => False...这些人在他们的unicode三明治理念中,接受几乎任何Python3中I/O库的静默decode('utf-8')。 - Red Pillsys.setdefaultencoding("utf-8")。 - nehem
sys.setdefaultencoding并不是解决方案。) 最后,如果你想看到它引起的错误,请参考这里:https://dev59.com/4V4b5IYBdhLWcg3w1UvL#28627705 - Konrad Rudolphsys.setdefaultencoding('utf-8')是个好主意而受到了影响。这里有另一个博客文章,其中有更多细节和进一步链接,也有人因此受到了影响。文章链接:https://opensourcehacker.com/2010/01/24/aptana-studio-eclipse-pydev-default-unicode-encoding/ - Lukas Graf