更新: 我最初的答案同意解决方案,但经过仔细思考,我认为解决方案是错误的。这个答案是从头重新编写的,请仔细阅读。我展示了为什么在时间T=16进入快速恢复,并且为什么协议保留在那里直到T=22。图表中的数据支持我的理论,所以我非常确定解决方案是错误的。
让我们先澄清一些事情:慢启动呈指数增长;拥塞避免呈线性增长,而快速恢复尽管使用与慢启动相同的公式来更新值,但也呈线性增长。
让我来解释一下。
为什么我们说慢启动呈指数增长?
请注意,每收到一个ACK就会增加字节。
让我们看一个例子。假设初始化为1 MSS(MSS的值通常为1460字节,因此实际上初始化为1460)。此时,由于拥塞窗口大小只能容纳1个数据包,TCP将不发送新数据,直到该数据包得到确认。假设ACK未丢失,则这意味着大约每个RTT秒传输一个新数据包(回想一下RTT是往返时间),因为我们需要(1/2)* RTT来发送数据包,以及(1/2)* RTT来接收ACK。
因此,这导致发送速率大约为MSS / RTT bps。现在,请记住,对于每个,都会增加。因此,一旦第一个到达,变为<2*MSS>,因此现在我们可以发送2个数据包。当这两个数据包被确认时,我们将增加两次,因此现在为<4*MSS>。太好了!我们可以发送4个数据包。这些4个数据包被确认,所以我们要增加 4次!因此我们有。然后我们得到。我们实际上是每个RTT秒使翻倍(这也解释了为什么在拥塞避免中导致线性增长)。
是的,这很棘手,公式很容易让我们相信它是线性的 - 这是一个常见的误解,因为人们经常忘记这适用于每个确认的数据包。
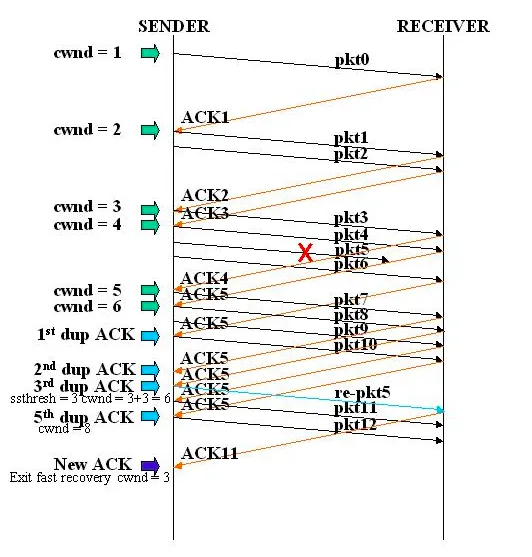
请注意,在现实世界中,传输4个数据包并不一定会生成4个ACK。可能只生成1个
ACK,但由于TCP使用累计确认,该单个
ACK仍然确认了4个数据包。
为什么快速恢复是线性的?
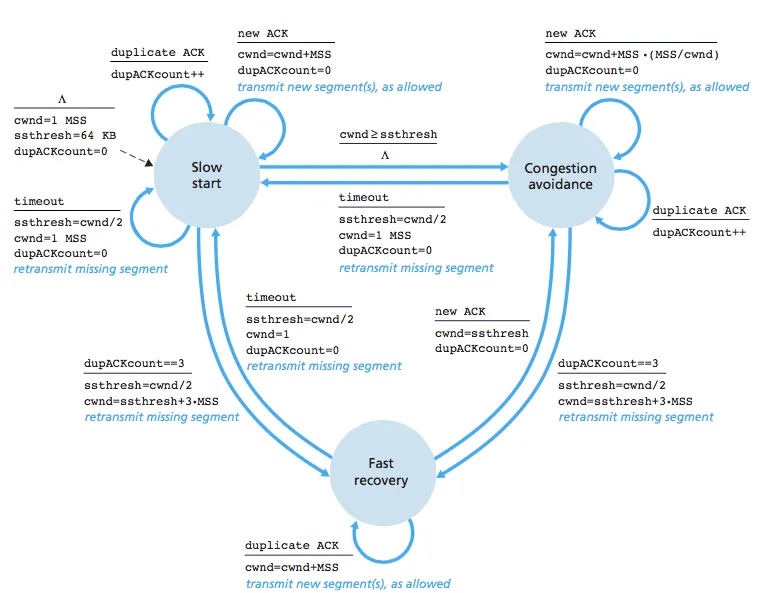
cwnd = cwnd + MSS公式在慢启动和拥塞避免中都适用。人们会认为这会导致两种状态都引起指数增长。然而,快速恢复将该公式应用于不同的上下文:当接收到重复的ACK时。其中的区别在于:在慢启动中,一个RTT确认了一堆段落,并且每个确认的段落都为
cwnd的新值贡献了+1MSS,而在快速恢复中,重复的ACK浪费了一个RTT来确认单个段落的丢失,因此我们不是每个RTT秒更新
cwnd N次(其中N是传输的段数),而是为丢失的一个段落更新
cwnd>一次。所以我们“浪费”了一个往返时间只有一个段落,所以我们只将cwnd增加1。
关于拥塞避免 - 当我分析图表时,我会解释这个。
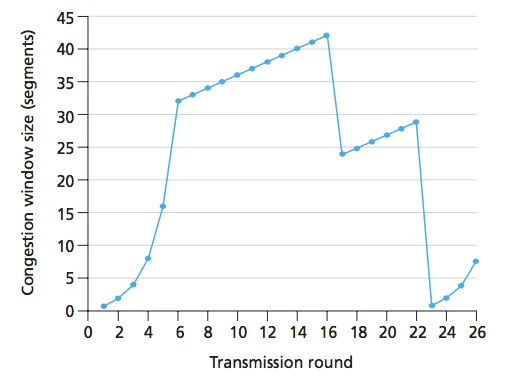
分析图表
好的,让我们逐一查看该图表中每一轮发生的情况。你的图片在某种程度上是正确的。首先让我澄清一些事情:
1.当我们说慢启动和快速恢复呈指数增长时,这意味着它在每一轮中呈指数增长,就像你在图片中展示的那样。所以,这是正确的。你正确地确定了用蓝色圆圈标出的回合:请注意,cwnd的值从一个圆圈到下一个圆圈呈指数增长- 1, 2, 4, 8, 16等。
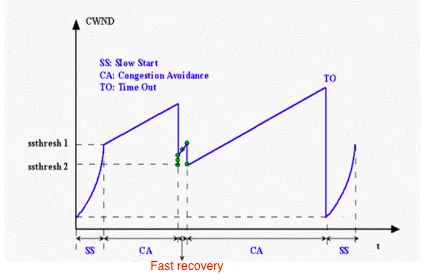
2.你的图片似乎表明协议从慢启动进入快速恢复状态。这不是发生的事情。如果从慢启动进入快速恢复,我们将看到cwnd减半。但是,图表所显示的并不是这样:从T = 6到T = 7,cwnd的值没有减少一半。
好的,现在让我们逐一查看每一轮发生的情况。请注意,图表中的时间单位是一轮。因此,如果在时间T = X时传输N个段落,则假定在时间T = X + 1时已经确认了这些N个段落(当然,假设它们没有丢失)。
还要注意,我们可以通过观察图表来确定ssthresh的值。在T=6时,cwnd停止指数增长并开始线性增长,它的值不会降低。从慢启动到另一个状态的唯一可能转换,不涉及减小cwnd的是转换到拥塞避免状态,当拥塞窗口大小等于ssthresh时发生。我们可以看到,在cwnd为32时,这种情况发生了。因此,我们立即知道ssthresh初始化为32 MSS。该书在第276页(图3.53)上显示了一个非常相似的图表,作者得出了类似的结论:
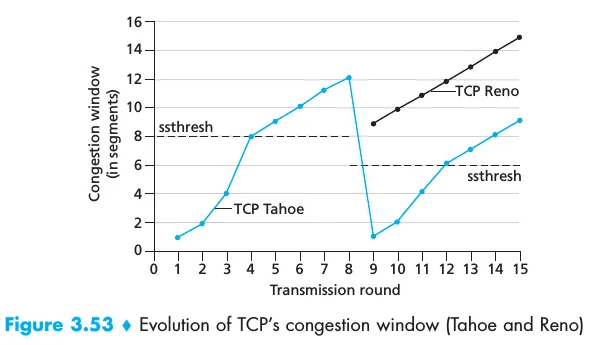 在正常情况下,当TCP第一次从指数增长转换为线性增长而不减小窗口大小时,它总是因为达到阈值并切换到拥塞避免。
在正常情况下,当TCP第一次从指数增长转换为线性增长而不减小窗口大小时,它总是因为达到阈值并切换到拥塞避免。
最后,假设MSS至少为1460字节(通常为1460字节,因为以太网的MTU = 1500字节,我们需要考虑TCP + IP头的大小,它们共需40字节)。当cwnd超过ssthresh时,这很重要,因为cwnd的单位是MSS,而ssthresh以字节表示。
因此,我们有:
T = 1:
cwnd = 1 MSS;ssthresh = 32 kB
传输1个段
T = 2:
1个段被确认
cwnd += 1;ssthresh = 32 kB
cwnd的新值:2
传输2个段
T = 3:
2个段被确认
cwnd += 2;ssthresh = 32 kB
cwnd的新值:4
传输4个段
T = 4:
4个段被确认
cwnd += 4;ssthresh = 32 kB
cwnd的新值:8
传输8个段
T = 5:
8个段被确认
cwnd += 8;ssthresh = 32 kB
cwnd的新值:16
传输16个段
T = 6:
16个段被确认
cwnd += 16;ssthresh = 32 kB
cwnd的新值:32
发送32个数据段
好的,现在让我们看看会发生什么。 cwnd 达到了 ssthresh(32*1460 = 46720字节,大于32000)。现在是切换到拥塞避免的时候了。请注意,每一轮中 cwnd 的值呈指数增长,因为每个确认的数据包都会对新的 cwnd 值贡献1 MSS,而每个发送的数据包都会在下一轮中得到确认。
切换到拥塞避免模式
现在,cwnd 不会再呈指数增长,因为每个 ACK 不再贡献1 MSS。相反,每个 ACK 贡献的是 MSS*(MSS/cwnd)。例如,如果 MSS 是1460字节,cwnd 是14600字节(因此在每一轮中我们发送10个数据段),那么每个 ACK (假设每个数据段都有一个 ACK)将使 cwnd 增加 1/10 MSS(146字节)。因为我们发送了10个数据段,并且在每轮结束时我们假设每个数据段都得到了确认,所以在每轮结束时,我们将 cwnd 增加了 10 * 1/10 = 1。换句话说,每个数据段只贡献一小部分的 cwnd,因此我们每轮只会将 cwnd 增加1 MSS,而不是增加传输/确认的数据段数量。
我们将保持拥塞避免模式,直到检测到某些丢失(无论是3个重复的 ACK 还是超时)。
现在,让时钟继续...
T = 7
已确认32个数据段
cwnd += 1; ssthresh = 32 kB
新的 cwnd 值:33
发送33个数据段
请注意,尽管已确认了32个数据段,但 cwnd 从32变为33(因此每个 ACK 贡献1/32)。如果像T=6那样处于慢启动状态,我们将会有 cwnd += 32。这个新的 cwnd 值也与时间T=7时图表中看到的值相符。
T = 8
已确认33个数据段
cwnd += 1; ssthresh = 32 kB
新的 cwnd 值:34
发送34个数据段
T = 9
已确认34个数据段
cwnd += 1; ssthresh = 32 kB
cwnd的新值为:35
传输35个分段
注意,这与图表一致:在T = 9时,我们有cwnd = 35。这一直持续到T = 16...
T = 10
确认35个分段
cwnd += 1; ssthresh = 32 kB
cwnd的新值为:36
传输36个分段
T = 11
确认36个分段
cwnd += 1; ssthresh = 32 kB
cwnd的新值为:37
传输37个分段
T = 12
确认37个分段
cwnd += 1; ssthresh = 32 kB
cwnd的新值为:38
传输38个分段
T = 13
确认38个分段
cwnd += 1; ssthresh = 32 kB
cwnd的新值为:39
传输39个分段
T = 14
确认39个分段
cwnd += 1; ssthresh = 32 kB
cwnd的新值为:40
传输40个分段
T = 15
确认40个分段
cwnd += 1; ssthresh = 32 kB
cwnd的新值为:41
传输41个分段
T = 16
确认41个分段
cwnd += 1; ssthresh = 32 kB
cwnd的新值为:42
传输42个分段
暂停
现在会发生什么?图表显示,拥塞窗口大小减小到大约一半大小,然后再次线性增长。唯一可能的情况是出现了3个重复的ACK,并且协议切换到快速恢复。图表显示它不会切换到慢启动,因为那会将cwnd降至1。因此,唯一可能的转换是快速恢复。
通过进入快速恢复,我们得到ssthresh = cwnd/2。记住cwnd的单位是MSS,而ssthresh以字节为单位,我们必须小心处理。因此,新值为ssthresh = cwnd*MSS/2 = 42*1460/2 = 30660。
再次注意,这与图表相符;请注意,当cwnd略小于30时(回想一下,对于MSS=1460,比率不完全是1:1,这就是为什么即使拥塞窗口大小略低于30,我们也会达到阈值),
ssthresh将在不久的将来被触发。
切换到拥塞避免还会导致
cwnd的新值为
ssthresh+3MSS=21+3=24(请注意单位,这里我又将
ssthresh转换成了MSS,因为我们的
cwnd值是以MSS计算的)。
截至目前,我们处于拥塞避免状态,T=17,
ssthresh=30660字节,
cwnd=24。
进入T=18后,可能会发生两件事情:要么我们收到重复的ACK,要么没有。如果没有(所以是新的ACK),我们将过渡到拥塞避免。但这会将
cwnd降至
ssthresh的值,即21。这与图表不符——图表显示
cwnd保持线性增长。此外,它不会切换到慢启动,因为那会将
cwnd降至1。这意味着快速恢复已经无法使用,我们正在收到重复的ACK。这会一直持续到时间T=22:
T = 18
收到重复的ACK
cwnd += 1;
ssthresh=30660字节
cwnd的新值:25
T = 19
收到重复的ACK
cwnd += 1;
ssthresh=30660字节
cwnd的新值:26
T = 20
收到重复的ACK
cwnd += 1;
ssthresh=30660字节
cwnd的新值:27
T = 21
收到重复的ACK
cwnd += 1;
ssthresh=30660字节
cwnd的新值:28
T = 22
收到重复的ACK
cwnd += 1;
ssthresh=30660字节
cwnd的新值:29
** 暂停 **
我们仍处于快速恢复阶段,现在突然下降到1。这表明它再次进入慢启动状态。 新的值将为
29 * 1460/2 = 21170,的新值为
1。这也意味着尽管我们努力重传数据段,但已超时。
T = 23
cwnd = 1; ssthresh = 21170字节
传输1个数据段
T = 24
确认1个数据段
cwnd += 1; ssthresh = 21170字节
cwnd的新值为:2
传输2个数据段
T = 25
确认2个数据段
cwnd += 2; ssthresh = 21170字节
cwnd的新值为:4
传输4个数据段
T = 26
确认4个数据段
cwnd += 4; ssthresh = 21170字节
cwnd的新值为:8
传输8个数据段
...
希望以上内容能让您更加清晰明了。
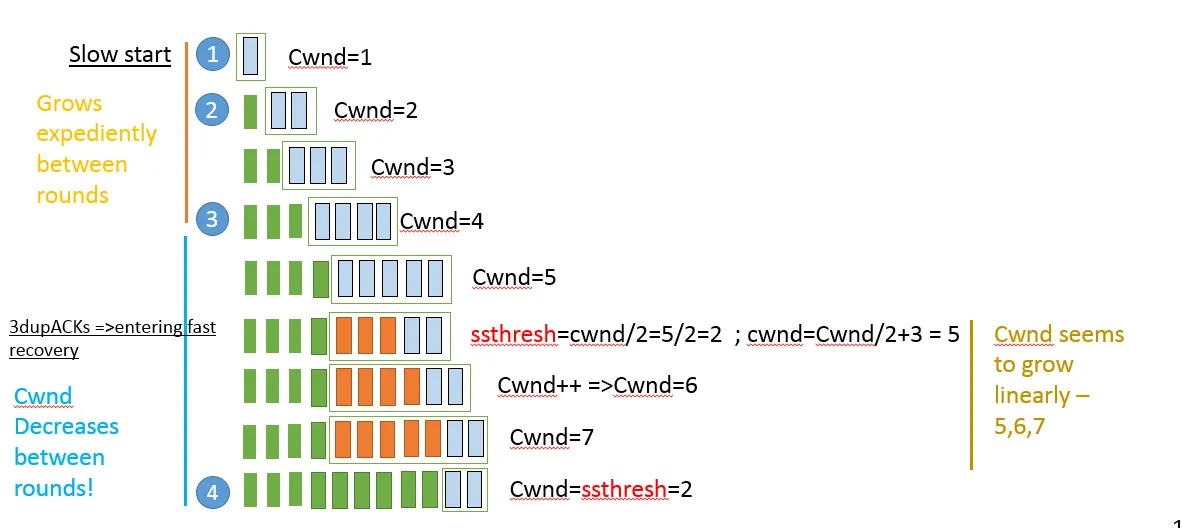 为什么在快速恢复状态下cwnd会呈指数增长?(在图像中我错误地写成了“expediently”而不是“exponentially”)
为什么在快速恢复状态下cwnd会呈指数增长?(在图像中我错误地写成了“expediently”而不是“exponentially”)