我需要做类似的事情来生成Doxygen Markdown表格,所以我想分享一下。我已经在Python 2.7和3.3中成功运行了示例代码,尽管我不能声称我已经进行了严格的测试。
left_rule = {'<': ':', '^': ':', '>': '-'}
right_rule = {'<': '-', '^': ':', '>': ':'}
def evalute_field(record, field_spec):
"""
Evalute a field of a record using the type of the field_spec as a guide.
"""
if type(field_spec) is int:
return str(record[field_spec])
elif type(field_spec) is str:
return str(getattr(record, field_spec))
else:
return str(field_spec(record))
def table(file, records, fields, headings, alignment = None):
"""
Generate a Doxygen-flavor Markdown table from records.
file -- Any object with a 'write' method that takes a single string
parameter.
records -- Iterable. Rows will be generated from this.
fields -- List of fields for each row. Each entry may be an integer,
string or a function. If the entry is an integer, it is assumed to be
an index of each record. If the entry is a string, it is assumed to be
a field of each record. If the entry is a function, it is called with
the record and its return value is taken as the value of the field.
headings -- List of column headings.
alignment - List of pairs alignment characters. The first of the pair
specifies the alignment of the header, (Doxygen won't respect this, but
it might look good, the second specifies the alignment of the cells in
the column.
Possible alignment characters are:
'<' = Left align (default for cells)
'>' = Right align
'^' = Center (default for column headings)
"""
num_columns = len(fields)
assert len(headings) == num_columns
columns = [[] for i in range(num_columns)]
for record in records:
for i, field in enumerate(fields):
columns[i].append(evalute_field(record, field))
extended_align = alignment if alignment != None else []
if len(extended_align) > num_columns:
extended_align = extended_align[0:num_columns]
elif len(extended_align) < num_columns:
extended_align += [('^', '<')
for i in range[num_columns-len(extended_align)]]
heading_align, cell_align = [x for x in zip(*extended_align)]
field_widths = [len(max(column, key=len)) if len(column) > 0 else 0
for column in columns]
heading_widths = [max(len(head), 2) for head in headings]
column_widths = [max(x) for x in zip(field_widths, heading_widths)]
_ = ' | '.join(['{:' + a + str(w) + '}'
for a, w in zip(heading_align, column_widths)])
heading_template = '| ' + _ + ' |'
_ = ' | '.join(['{:' + a + str(w) + '}'
for a, w in zip(cell_align, column_widths)])
row_template = '| ' + _ + ' |'
_ = ' | '.join([left_rule[a] + '-'*(w-2) + right_rule[a]
for a, w in zip(cell_align, column_widths)])
ruling = '| ' + _ + ' |'
file.write(heading_template.format(*headings).rstrip() + '\n')
file.write(ruling.rstrip() + '\n')
for row in zip(*columns):
file.write(row_template.format(*row).rstrip() + '\n')
这是一个简单的测试案例:
import sys
sys.stdout.write('State Capitals (source: Wikipedia)\n\n')
headings = ['State', 'Abrev.', 'Capital', 'Capital since', 'Population',
'Largest Population?']
data = [('Alabama', 'AL', '1819', 'Montgomery', '1846', 155.4, False,
205764),
('Alaska', 'AK', '1959', 'Juneau', '1906', 2716.7, False, 31275),
('Arizona', 'AZ', '1912', 'Phoenix', '1889',474.9, True, 1445632),
('Arkansas', 'AR', '1836', 'Little Rock', '1821', 116.2, True,
193524)]
fields = [0, 1, 3, 4, 7, lambda rec: 'Yes' if rec[6] else 'No']
align = [('^', '<'), ('^', '^'), ('^', '<'), ('^', '^'), ('^', '>'),
('^','^')]
table(sys.stdout, data, fields, headings, align)
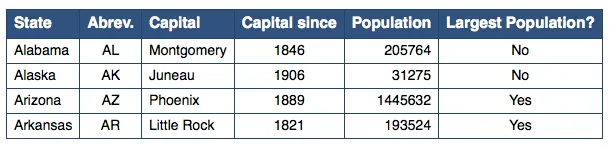
输出如下:
State Capitals (source: Wikipedia)
| State | Abrev. | Capital | Capital since | Population | Largest Population? |
| :------- | :----: | :---------- | :-----------: | ---------: | :-----------------: |
| Alabama | AL | Montgomery | 1846 | 205764 | No |
| Alaska | AK | Juneau | 1906 | 31275 | No |
| Arizona | AZ | Phoenix | 1889 | 1445632 | Yes |
| Arkansas | AR | Little Rock | 1821 | 193524 | Yes |
Doxygen 将其呈现为: