我写了一个文本分类程序。当我运行这个程序时,它会崩溃并显示如下截图中的错误信息:
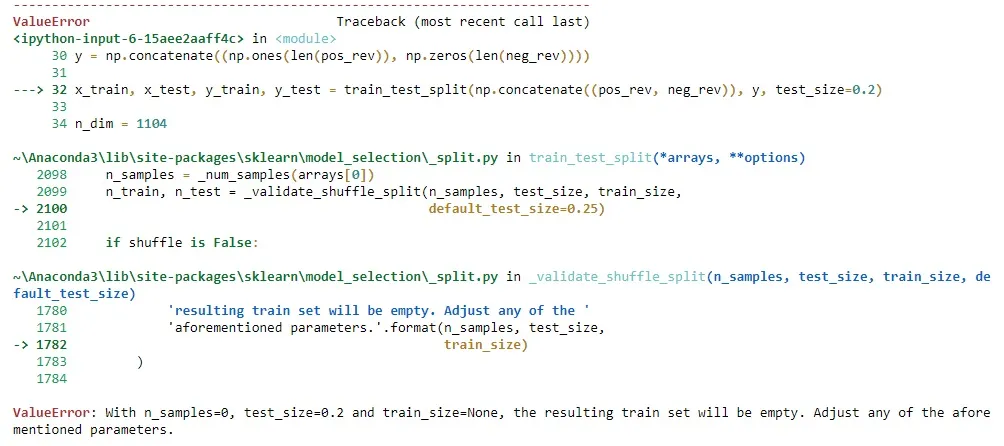
数值错误:当n_samples=0,test_size=0.2且train_size=None时,生成的训练集将为空。请调整上述任何参数。
这是我的代码:
from sklearn.model_selection import train_test_split
from gensim.models.word2vec import Word2Vec
from sklearn.preprocessing import scale
from sklearn.linear_model import SGDClassifier
import nltk, string, json
import numpy as np
def cleanText(corpus):
reviews = []
for dd in corpus:
#for d in dd:
try:
words = nltk.word_tokenize(dd['description'])
words = [w.lower() for w in words]
reviews.append(words)
#break
except:
pass
return reviews
with open('C:\\NLP\\bad.json') as fin:
text = json.load(fin)
neg_rev = cleanText(text)
with open('C:\\NLP\\good.json') as fin:
text = json.load(fin)
pos_rev = cleanText(text)
#1 for positive sentiment, 0 for negative
y = np.concatenate((np.ones(len(pos_rev)), np.zeros(len(neg_rev))))
x_train, x_test, y_train, y_test = train_test_split(np.concatenate((pos_rev, neg_rev)), y, test_size=0.2)
我使用的数据在这里可用:
我该如何解决这个错误?
y变量的shape了吗? - G. Andersonn_samples=0。所以从那里开始倒推,弄清楚在pos_rev和neg_rev中实际上是什么被解析出来的,因为如果没有错误,那么每个的len()似乎都是0。 - G. Anderson