我正在抓取以下页面:https://proximity.niceic.com/mainform.aspx
首先,请在国家文本框中输入“%%”以显示该地区的所有承包商。一旦进入,如果我检查开发工具中的HTML,我会得到以下内容:
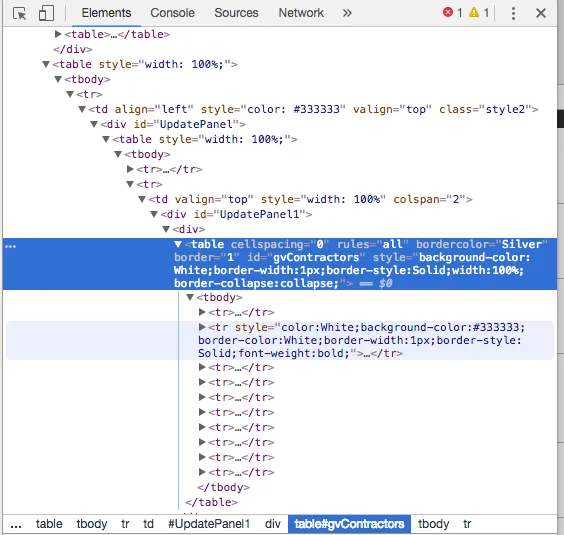 我想从所选表格中提取所有信息。问题是,当我使用selenium进行抓取时,我找到了表格,但无法访问其主体或子项。
我想从所选表格中提取所有信息。问题是,当我使用selenium进行抓取时,我找到了表格,但无法访问其主体或子项。
这是我的Python代码:
上述代码输出如下内容:
我想从所选表格中提取所有信息。问题是,当我使用selenium进行抓取时,我找到了表格,但无法访问其主体或子项。这是我的Python代码:
main_table = driver.find_elements_by_tag_name('table')
outer_table = main_table[3].find_element_by_tag_name('table')
print outer_table.get_attribute('innerHTML')
上述代码输出如下内容:
<table cellspacing="0" rules="all" bordercolor="Silver" border="1" id="dvContractorDetail" style="background-color:White;border-color:Silver;border-width:1px;border-style:Solid;height:200px;width:400px;border-collapse:collapse;">
</table>如您所见,我仅能获取表格标签,却获取不到其下组件tbody或tbody标签下的所有tr标签。
我该怎么办?