在进行perfplot分析后,建议采用缓冲读取解决方案。
def buf_count_newlines_gen(fname):
def _make_gen(reader):
while True:
b = reader(2 ** 16)
if not b: break
yield b
with open(fname, "rb") as f:
count = sum(buf.count(b"\n") for buf in _make_gen(f.raw.read))
return count
它快速且占用内存少。大多数其他解决方案要慢20倍左右。
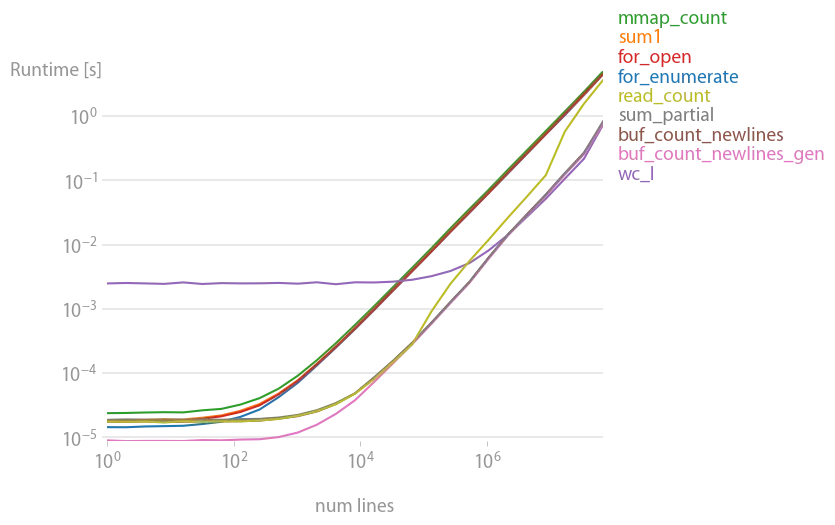
生成该图的代码:
import mmap
import subprocess
from functools import partial
import perfplot
def setup(n):
fname = "t.txt"
with open(fname, "w") as f:
for i in range(n):
f.write(str(i) + "\n")
return fname
def for_enumerate(fname):
i = 0
with open(fname) as f:
for i, _ in enumerate(f):
pass
return i + 1
def sum1(fname):
return sum(1 for _ in open(fname))
def mmap_count(fname):
with open(fname, "r+") as f:
buf = mmap.mmap(f.fileno(), 0)
lines = 0
while buf.readline():
lines += 1
return lines
def for_open(fname):
lines = 0
for _ in open(fname):
lines += 1
return lines
def buf_count_newlines(fname):
lines = 0
buf_size = 2 ** 16
with open(fname) as f:
buf = f.read(buf_size)
while buf:
lines += buf.count("\n")
buf = f.read(buf_size)
return lines
def buf_count_newlines_gen(fname):
def _make_gen(reader):
b = reader(2 ** 16)
while b:
yield b
b = reader(2 ** 16)
with open(fname, "rb") as f:
count = sum(buf.count(b"\n") for buf in _make_gen(f.raw.read))
return count
def wc_l(fname):
return int(subprocess.check_output(["wc", "-l", fname]).split()[0])
def sum_partial(fname):
with open(fname) as f:
count = sum(x.count("\n") for x in iter(partial(f.read, 2 ** 16), ""))
return count
def read_count(fname):
return open(fname).read().count("\n")
b = perfplot.bench(
setup=setup,
kernels=[
for_enumerate,
sum1,
mmap_count,
for_open,
wc_l,
buf_count_newlines,
buf_count_newlines_gen,
sum_partial,
read_count,
],
n_range=[2 ** k for k in range(27)],
xlabel="num lines",
)
b.save("out.png")
b.show()
enumerate(f, 1)代替range(len(f))并省略i + 1? - Ian Mackinnon