我有一个包含浮点类型字段的数据结构。一组这些结构需要按浮点值进行排序。是否有针对此类排序的基数排序实现?
如果没有,是否有一种快速访问指数、符号和尾数的方法。因为如果您首先按尾数、指数排序,最后再按指数排序,您可以在O(n)时间内对浮点数进行排序。
我有一个包含浮点类型字段的数据结构。一组这些结构需要按浮点值进行排序。是否有针对此类排序的基数排序实现?
如果没有,是否有一种快速访问指数、符号和尾数的方法。因为如果您首先按尾数、指数排序,最后再按指数排序,您可以在O(n)时间内对浮点数进行排序。
更新:
我对这个主题非常感兴趣,所以我坐下来实现了它(使用这个非常快速和内存保守的实现)。我还阅读了这篇文章(感谢celion),发现你甚至不需要将浮点数分成尾数和指数来进行排序。你只需要一一取出比特并执行一个整数排序即可。你只需要关心负值,在算法的最后一次迭代中将它们反向放在正值的前面(我在一步中完成了这个操作,以节省一些 CPU 时间)。
因此,这是我的浮点数基数排序:
public static float[] RadixSort(this float[] array)
{
// temporary array and the array of converted floats to ints
int[] t = new int[array.Length];
int[] a = new int[array.Length];
for (int i = 0; i < array.Length; i++)
a[i] = BitConverter.ToInt32(BitConverter.GetBytes(array[i]), 0);
// set the group length to 1, 2, 4, 8 or 16
// and see which one is quicker
int groupLength = 4;
int bitLength = 32;
// counting and prefix arrays
// (dimension is 2^r, the number of possible values of a r-bit number)
int[] count = new int[1 << groupLength];
int[] pref = new int[1 << groupLength];
int groups = bitLength / groupLength;
int mask = (1 << groupLength) - 1;
int negatives = 0, positives = 0;
for (int c = 0, shift = 0; c < groups; c++, shift += groupLength)
{
// reset count array
for (int j = 0; j < count.Length; j++)
count[j] = 0;
// counting elements of the c-th group
for (int i = 0; i < a.Length; i++)
{
count[(a[i] >> shift) & mask]++;
// additionally count all negative
// values in first round
if (c == 0 && a[i] < 0)
negatives++;
}
if (c == 0) positives = a.Length - negatives;
// calculating prefixes
pref[0] = 0;
for (int i = 1; i < count.Length; i++)
pref[i] = pref[i - 1] + count[i - 1];
// from a[] to t[] elements ordered by c-th group
for (int i = 0; i < a.Length; i++){
// Get the right index to sort the number in
int index = pref[(a[i] >> shift) & mask]++;
if (c == groups - 1)
{
// We're in the last (most significant) group, if the
// number is negative, order them inversely in front
// of the array, pushing positive ones back.
if (a[i] < 0)
index = positives - (index - negatives) - 1;
else
index += negatives;
}
t[index] = a[i];
}
// a[]=t[] and start again until the last group
t.CopyTo(a, 0);
}
// Convert back the ints to the float array
float[] ret = new float[a.Length];
for (int i = 0; i < a.Length; i++)
ret[i] = BitConverter.ToSingle(BitConverter.GetBytes(a[i]), 0);
return ret;
}
由于在函数的开始和结束处需要将浮点数按位复制到整数中,然后再复制回来,因此它比int基数排序略慢。尽管如此,整个函数仍然是O(n)的。无论如何,比你提出的连续排序3次要快得多。我不认为还有太多优化的空间,但如果有人有建议,请随时告诉我。
要按降序排序,请更改最后一行:
ret[i] = BitConverter.ToSingle(BitConverter.GetBytes(a[i]), 0);
转换为:
ret[a.Length - i - 1] = BitConverter.ToSingle(BitConverter.GetBytes(a[i]), 0);
测量:
我设置了一些短测试,包含所有浮点数的特殊情况(NaN、+/-Inf、最小/最大值、0)和随机数。它按照与 Linq 或 Array.Sort 排序浮点数完全相同的顺序进行排序:
NaN -> -Inf -> Min -> Negative Nums -> 0 -> Positive Nums -> Max -> +Inf
我进行了一个包含1000万个数字的庞大数组的测试:
float[] test = new float[10000000];
Random rnd = new Random();
for (int i = 0; i < test.Length; i++)
{
byte[] buffer = new byte[4];
rnd.NextBytes(buffer);
float rndfloat = BitConverter.ToSingle(buffer, 0);
switch(i){
case 0: { test[i] = float.MaxValue; break; }
case 1: { test[i] = float.MinValue; break; }
case 2: { test[i] = float.NaN; break; }
case 3: { test[i] = float.NegativeInfinity; break; }
case 4: { test[i] = float.PositiveInfinity; break; }
case 5: { test[i] = 0f; break; }
default: { test[i] = test[i] = rndfloat; break; }
}
}
并停止了不同排序算法的时间:
Stopwatch sw = new Stopwatch();
sw.Start();
float[] sorted1 = test.RadixSort();
sw.Stop();
Console.WriteLine(string.Format("RadixSort: {0}", sw.Elapsed));
sw.Reset();
sw.Start();
float[] sorted2 = test.OrderBy(x => x).ToArray();
sw.Stop();
Console.WriteLine(string.Format("Linq OrderBy: {0}", sw.Elapsed));
sw.Reset();
sw.Start();
Array.Sort(test);
float[] sorted3 = test;
sw.Stop();
Console.WriteLine(string.Format("Array.Sort: {0}", sw.Elapsed));
输出结果为(更新:现在使用发布版本而非调试版本运行):
RadixSort: 00:00:03.9902332
Linq OrderBy: 00:00:17.4983272
Array.Sort: 00:00:03.1536785
大约比Linq快四倍以上。这并不差。但仍然不如Array.Sort快,但也没有那么糟糕。但是我真的对这个感到惊讶:我预计它在非常小的数组上会比Linq慢一点。但后来我进行了一个只有20个元素的测试:
RadixSort: 00:00:00.0012944
Linq OrderBy: 00:00:00.0072271
Array.Sort: 00:00:00.0002979
即使这次我的Radixsort比Linq更快,但比数组排序慢得多。:)
更新2:
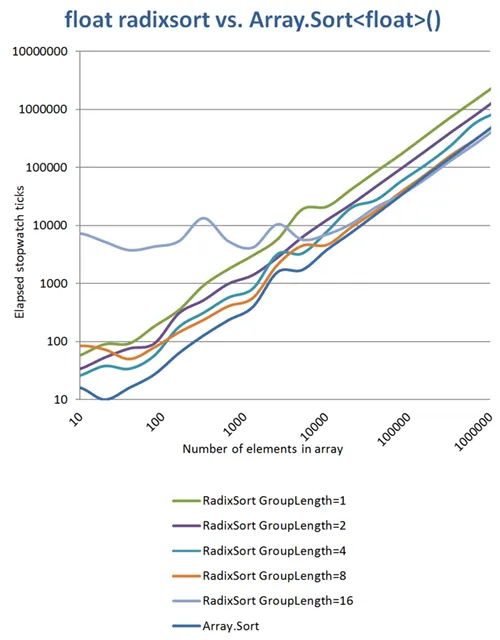
我进行了更多的测量并发现了一些有趣的事情:较长的组长度常数意味着较少的迭代和更多的内存使用。如果您使用16位组长度(仅2次迭代),则在对小数组排序时会有巨大的内存开销,但是即使没有太多,在处理大约100,000个元素的数组时,您仍然可以击败Array.Sort。图表轴都是对数化的:
(来源:daubmeier.de)
static public void RadixSortFloat(this float[] array, int arrayLen = -1)
{
// Some use cases have an array that is longer as the filled part which we want to sort
if (arrayLen < 0) arrayLen = array.Length;
// Cast our original array as long
Span<float> asFloat = array;
Span<int> a = MemoryMarshal.Cast<float, int>(asFloat);
// Create a temp array
Span<int> t = new Span<int>(new int[arrayLen]);
// set the group length to 1, 2, 4, 8 or 16 and see which one is quicker
int groupLength = 8;
int bitLength = 32;
// counting and prefix arrays
// (dimension is 2^r, the number of possible values of a r-bit number)
var dim = 1 << groupLength;
int groups = bitLength / groupLength;
if (groups % 2 != 0) throw new Exception("groups must be even so data is in original array at end");
var count = new int[dim];
var pref = new int[dim];
int mask = (dim) - 1;
int negatives = 0, positives = 0;
// counting elements of the 1st group incuding negative/positive
for (int i = 0; i < arrayLen; i++)
{
if (a[i] < 0) negatives++;
count[(a[i] >> 0) & mask]++;
}
positives = arrayLen - negatives;
int c;
int shift;
for (c = 0, shift = 0; c < groups - 1; c++, shift += groupLength)
{
CalcPrefixes();
var nextShift = shift + groupLength;
//
for (var i = 0; i < arrayLen; i++)
{
var ai = a[i];
// Get the right index to sort the number in
int index = pref[( ai >> shift) & mask]++;
count[( ai>> nextShift) & mask]++;
t[index] = ai;
}
// swap the arrays and start again until the last group
var temp = a;
a = t;
t = temp;
}
// Last round
CalcPrefixes();
for (var i = 0; i < arrayLen; i++)
{
var ai = a[i];
// Get the right index to sort the number in
int index = pref[( ai >> shift) & mask]++;
// We're in the last (most significant) group, if the
// number is negative, order them inversely in front
// of the array, pushing positive ones back.
if ( ai < 0) index = positives - (index - negatives) - 1; else index += negatives;
//
t[index] = ai;
}
void CalcPrefixes()
{
pref[0] = 0;
for (int i = 1; i < dim; i++)
{
pref[i] = pref[i - 1] + count[i - 1];
count[i - 1] = 0;
}
}
}
这里有一个关于如何对浮点数进行基数排序的很好的解释: http://www.codercorner.com/RadixSortRevisited.htm
如果您的所有值都是正数,您可以使用二进制表示;该链接解释了如何处理负值。
您可以使用unsafe块来进行memcpy或将float *别名为uint *以提取位。
如果数值之间的差距不太接近且需要有合理的精度要求,我认为最好的方法是使用实际的浮点数位在小数点前后进行排序。
例如,您可以只使用前4个小数位(无论它们是否为0)来进行排序。
{kind=link}