前几天我在想是否可以从Mathematica访问StackOverflow的API,后来发现确实有:"Saving plot annotations"
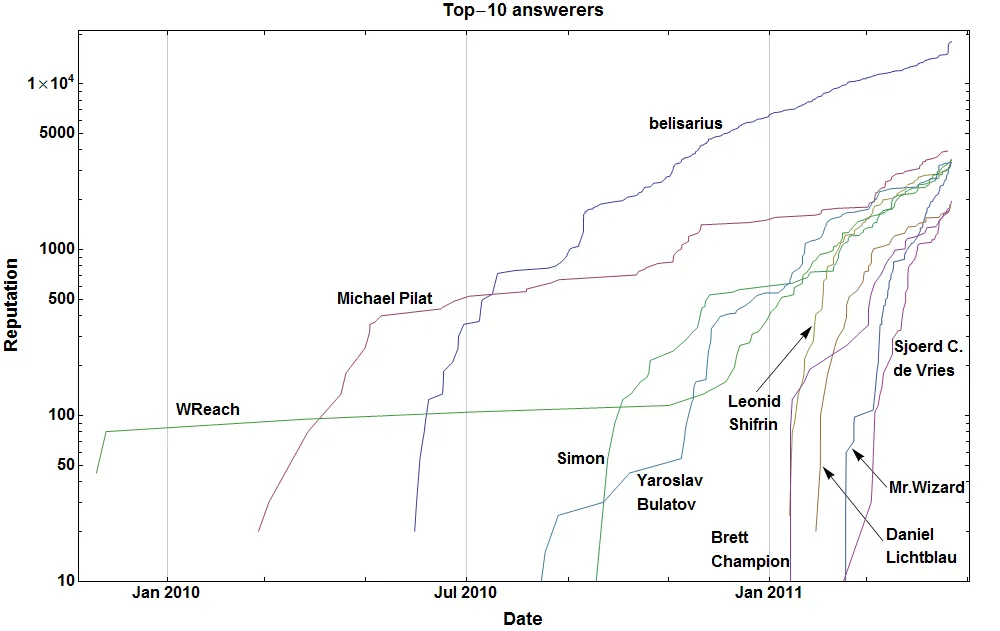
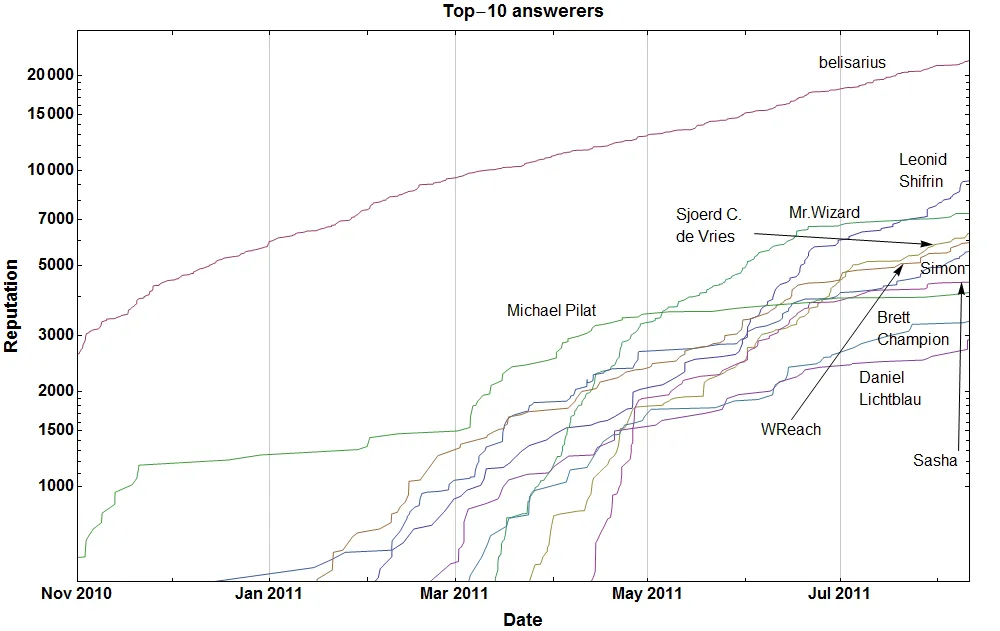
如何最好地将数据从StackOverflow导入Mathematica?Sjoerd使用这些信息制作了一个图表。我想在我的笔记本中保留一个停靠单元格,添加与StackOverflow相关的通知,以便我可以在不离开Mathematica的情况下知道是否有更新或响应。
前几天我在想是否可以从Mathematica访问StackOverflow的API,后来发现确实有:"Saving plot annotations"
如何最好地将数据从StackOverflow导入Mathematica?Sjoerd使用这些信息制作了一个图表。我想在我的笔记本中保留一个停靠单元格,添加与StackOverflow相关的通知,以便我可以在不离开Mathematica的情况下知道是否有更新或响应。
根据广大用户的要求,使用SO API(这是一个相当不错和完整的API;有很多好东西。而且使用也很容易——请看我的代码)生成前10个SO回答者的图表代码(不包括注释)。
更新:添加了App-key,以确保代码更好地与SO-API协作(提高每日调用上限)。请仅为此应用程序使用它。
2011年4月
2011年8月
MMA 8版本!MMA7版本在下面
getRepChanges[userID_Integer] :=
Module[{totalChanges},
totalChanges =
"total" /.
Import["http://api.stackoverflow.com/1.1/users/" <>
ToString[userID] <> "/reputation?key=NgVJ4Y6vFkuF-oqI-eOvOw&fromdate=0&pagesize=1&page=1",
"JSON"
];
Join @@
Table[
"rep_changes" /.
Import["http://api.stackoverflow.com/1.1/users/" <>
ToString[userID] <>
"/reputation?key=NgVJ4Y6vFkuF-oqI-eOvOw&fromdate=0&pagesize=100&page="
<> ToString[page],
"JSON"
],
{page, 1, Ceiling[totalChanges/100]}
]
]
topAnswerers =
({"display_name","user_id", "email_hash"} /. #) & /@
("user" /.
("top_users" /.
Import[
"http://api.stackoverflow.com/1.1/tags/mathematica/top-answerers/all-time",
"JSON"
]
)
)
topAnswerers = {#, #2,
Import["http://www.gravatar.com/avatar/" <> #3 <> ".jpg?s=36&d=identicon&d=identicon"]
} & @@@ topAnswerers
repChangesTopUsers =
Table[
repChange =
ReleaseHold[
(
Hold[
{
DateList["on_date" + AbsoluteTime["January 1, 1970"]],
"positive_rep" - "negative_rep"
}
] /. #
) & /@ getRepChanges[userID]
] // Sort;
accRepChange = {repChange[[All, 1]],Accumulate[repChange[[All, 2]]]}\[Transpose],
{userID, topAnswerers[[All, 2]]}
];
pl = DateListLogPlot[
Tooltip @@@
Take[({repChangesTopUsers, Row /@ topAnswerers[[All, {3, 1}]]}\[Transpose]),
10], Joined -> True, Mesh -> None, ImageSize -> 1000,
PlotRange -> {All, {10, All}},
BaseStyle -> {FontFamily -> "Arial-Bold", FontSize -> 16},
DateTicksFormat -> {"MonthNameShort", " ", "Year"},
GridLines -> {True, None},
FrameLabel -> (Style[#, FontSize -> 18] & /@ {"Date", "Reputation",
"Top-10 answerers", ""})]
getRepChanges[userID_Integer] :=
Module[{totalChanges},
totalChanges =
"total" /.
ImportString[
StringReplace[(Import[
"http://api.stackoverflow.com/1.1/users/" <>
ToString[userID] <>
"/reputation?key=NgVJ4Y6vFkuF-oqI-eOvOw&fromdate=0&pagesize=1&page=1", "Text"]), {":" ->
"->", "[" -> "{", "]" -> "}"}], "NB"];
Join @@
Table["rep_changes" /.
ImportString[
StringReplace[
Import["http://api.stackoverflow.com/1.1/users/" <>
ToString[userID] <>
"/reputation?key=NgVJ4Y6vFkuF-oqI-eOvOw&fromdate=0&pagesize=100&page=" <> ToString[page],
"Text"], {":" -> "->", "[" -> "{", "]" -> "}"}],
"NB"], {page, 1, Ceiling[totalChanges/100]}]]
topAnswerers = ({"display_name", "user_id",
"email_hash"} /. #) & /@ ("user" /. ("top_users" /.
ImportString[
StringReplace[
" " <> Import[
"http://api.stackoverflow.com/1.1/tags/mathematica/top-answerers/all-time", "Text"], {":" -> "->", "[" -> "{", "]" -> "}"}],
"NB"]))
topAnswerers = {#, #2,
Import["http://www.gravatar.com/avatar/" <> #3 <>
".jpg?s=36&d=identicon&d=identicon"]} & @@@ topAnswerers
repChangesTopUsers =
Table[repChange =
ReleaseHold[(Hold[{DateList[
"on_date" + AbsoluteTime["January 1, 1970"]],
"positive_rep" - "negative_rep"}] /. #) & /@
getRepChanges[userID]] // Sort;
accRepChange = {repChange[[All, 1]],
Accumulate[repChange[[All, 2]]]}\[Transpose], {userID,
topAnswerers[[All, 2]]}];
DateListLogPlot[
Tooltip @@@
Take[({repChangesTopUsers,
Row /@ topAnswerers[[All, {3, 1}]]}\[Transpose]), 10],
Joined -> True, Mesh -> None, ImageSize -> 1000,
PlotRange -> {All, {10, All}},
BaseStyle -> {FontFamily -> "Arial-Bold", FontSize -> 16},
DateTicksFormat -> {"MonthNameShort", " ", "Year"},
GridLines -> {True, None},
FrameLabel -> (Style[#, FontSize -> 18] & /@ {"Date", "Reputation",
"Top-10 answerers", ""})]
编辑:用于按帖子标签筛选的辅助函数
这些函数可用于过滤声望收益,以便仅查找特定标签的收益。
tagLookup将post_ID整数作为输入并生成特定帖子的标签。 getQuestionIDs和getAnswerIDsFrom...则相反。给定一个标签,它们会查找所有问题和答案的ID,以便可以使用MemberQ测试给定的post_ID是否属于该标签。由于需要进行许多API调用,因此tagLookup和getAnswerIDs都很慢。我无法测试最后两个函数,因为API访问要么不可用,要么我的IP已达到上限。
tagLookup[postID_Integer] :=
Module[{im},
im = Import["http://api.stackoverflow.com/1.1/questions/" <> ToString[postID],"JSON"];
If[("questions" /. im) != {},
First[("tags" /. ("questions" /. im))],
im = Import["http://api.stackoverflow.com/1.1/answers/" <> ToString[postID],"JSON"];
First[("tags" /. ("questions" /. Import["http://api.stackoverflow.com/1.1/questions/" <>
ToString[First["question_id" /. ("answers" /. im)]], "JSON"]))]
]
]
getQuestionIDs[tagName_String] := Module[{total},
total =
"total" /.
Import["http://api.stackoverflow.com/1.1/questions?tagged=" <>
tagName <> "&pagesize=1", "JSON"];
Join @@
Table[("question_id" /. ("questions" /.
Import["http://api.stackoverflow.com/1.1/questions?key=NgVJ4Y6vFkuF-oqI-eOvOw&tagged=" <>
tagName <> "&pagesize=100&page=" <> ToString[i],
"JSON"])), {i, 1, Ceiling[total/100]}]
]
getAnswerIDsFromQuestionID[questionID_Integer] :=
Module[{total},
total =
Import["http://api.stackoverflow.com/1.1/questions/" <>
ToString[questionID] <> "/answers?key=NgVJ4Y6vFkuF-oqI-eOvOw&pagesize=1", "JSON"];
If[total === $Failed, Return[$Failed], total = "total" /. total];
Join @@ Table[
"answer_id" /. ("answers" /.
Import["http://api.stackoverflow.com/1.1/questions/" <>
ToString[questionID] <> "/answers?key=NgVJ4Y6vFkuF-oqI-eOvOw&pagesize=100&page=" <>
ToString[i], "JSON"]), {i, 1, Ceiling[total/100]}]
]
getAnswerIDsFromTag[tagName_String] :=
Module[{},
Join @@ (getAnswerIDsFromQuestionID /@
Cases[getQuestionIDs[tagName], Except[$Failed]])
]
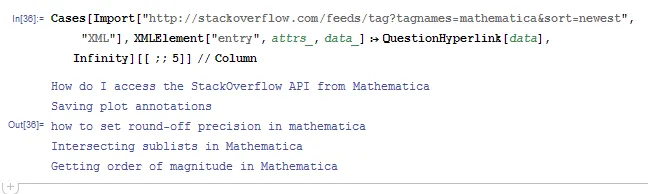
Brett,与SO API无关,但是你可以使用RSS提要获取最新的Mathematica标记问题。这是我的天真实现:
QuestionHyperlink[data_] :=
Function[{name, title, link},
Hyperlink[Tooltip[title, name], link]] @@ Join[
Cases[data,
XMLElement[
"author", _, {___, XMLElement["name", {}, {name_}], ___}] :>
name],
Cases[data, XMLElement["title", _, {title_}] :> title],
Cases[data, XMLElement["link", rules_, {}] :> ("href" /. rules)]]
Cases[Import[
"http://stackoverflow.com/feeds/tag?tagnames=mathematica&sort=\
newest", "XML"],
XMLElement["entry", attrs_, data_] :>
QuestionHyperlink[data], Infinity]