我不能区分ARM NEON指令中的
“vld4q_f32”指令及其相应的汇编指令如下所示:
在内部实现层面上,我看到的区别是返回类型,但是如果我查看汇编指令和寄存器数量,它们看起来都是相同的。编译器或汇编器如何知道两者之间的区别?
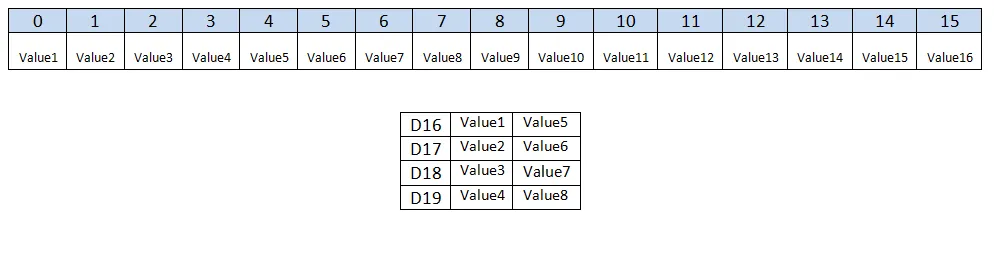
有人能否进一步澄清这一点,并解释一下如何将位于每个第四个内存位置的4个float32_t值加载到一个单独的寄存器中?
vld4_f32和vld4q_f32之间的差异。当我提高编码水平并开始查看汇编指令而不是信息较少的内部函数时,混淆开始了。我需要在这里使用vld4变体指令的原因是,我想从我的大型数组的每个第四个位置捕获4个float32_t。

vld4_f32 内置函数和相应的汇编指令如下所示(来自此链接)
float32x2x4_t vld4_f32 (const float32_t *)
Form of expected instruction(s): vld4.32 {d0, d1, d2, d3}, [r0]
“vld4q_f32”指令及其相应的汇编指令如下所示:
float32x4x4_t vld4q_f32 (const float32_t *)
Form of expected instruction(s): vld4.32 {d0, d1, d2, d3}, [r0]
在内部实现层面上,我看到的区别是返回类型,但是如果我查看汇编指令和寄存器数量,它们看起来都是相同的。编译器或汇编器如何知道两者之间的区别?
有人能否进一步澄清这一点,并解释一下如何将位于每个第四个内存位置的4个float32_t值加载到一个单独的寄存器中?