我的问题是关于 Codewars 上这个 kata:this。该函数接受两个已排序且元素不重复的列表作为参数。这些列表可能有共同的项,也可能没有。任务是找到最大路径和。在寻找和的过程中,如果有任何相同的项,您可以选择将您的路径更改为另一个列表。
给定的示例如下:
list1 = [0, 2, 3, 7, 10, 12]
list2 = [1, 5, 7, 8]
0->2->3->7->10->12 => 34
0->2->3->7->8 => 20
1->5->7->8 => 21
1->5->7->10->12 => 35 (maximum path)
我完成了这道题目,但我的代码未能达到性能要求,因此我遇到了执行超时的问题。我该怎么办?
这是我的解决方案:
def max_sum_path(l1:list, l2:list):
common_items = list(set(l1).intersection(l2))
if not common_items:
return max(sum(l1), sum(l2))
common_items.sort()
s = 0
new_start1 = 0
new_start2 = 0
s1 = 0
s2 = 0
for item in common_items:
s1 = sum(itertools.islice(l1, new_start1, l1.index(item)))
s2 = sum(itertools.islice(l2, new_start2, l2.index(item)))
new_start1 = l1.index(item)
new_start2 = l2.index(item)
s += max(s1, s2)
s1 = sum(itertools.islice(l1, new_start1, len(l1)))
s2 = sum(itertools.islice(l2, new_start2, len(l2)))
s += max(s1, s2)
return s
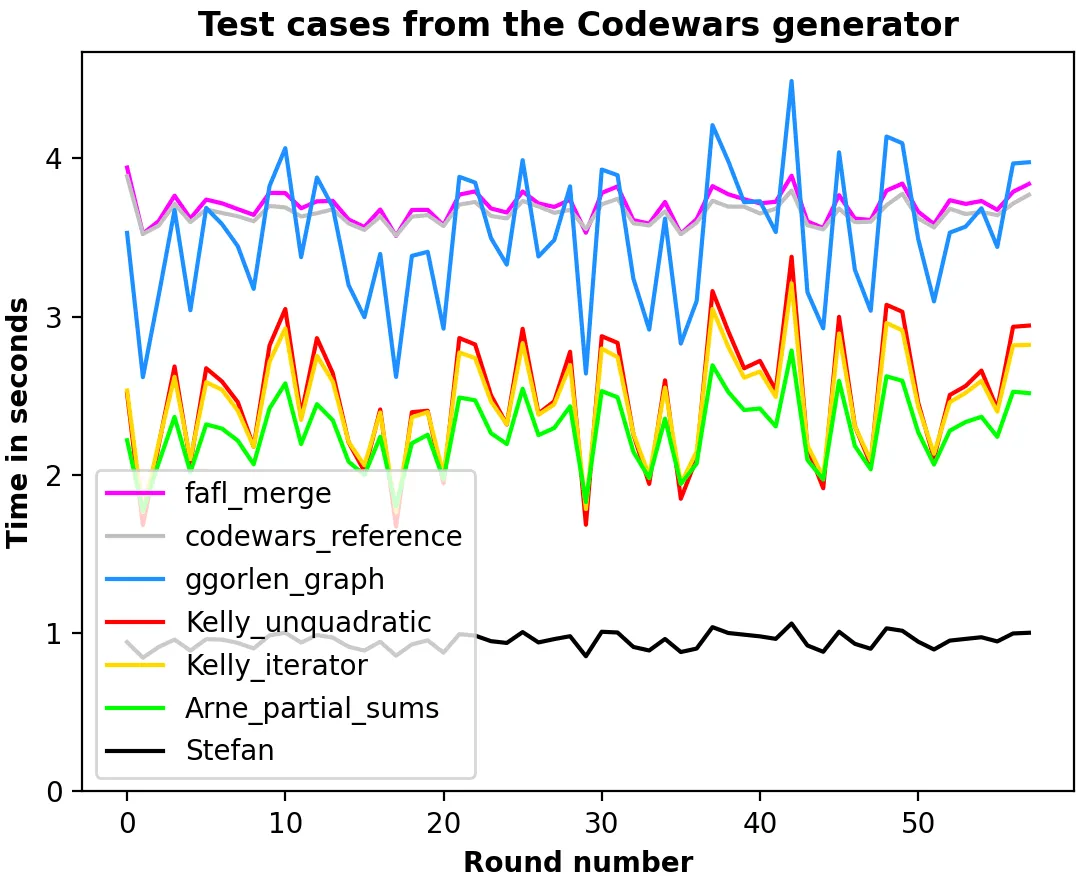
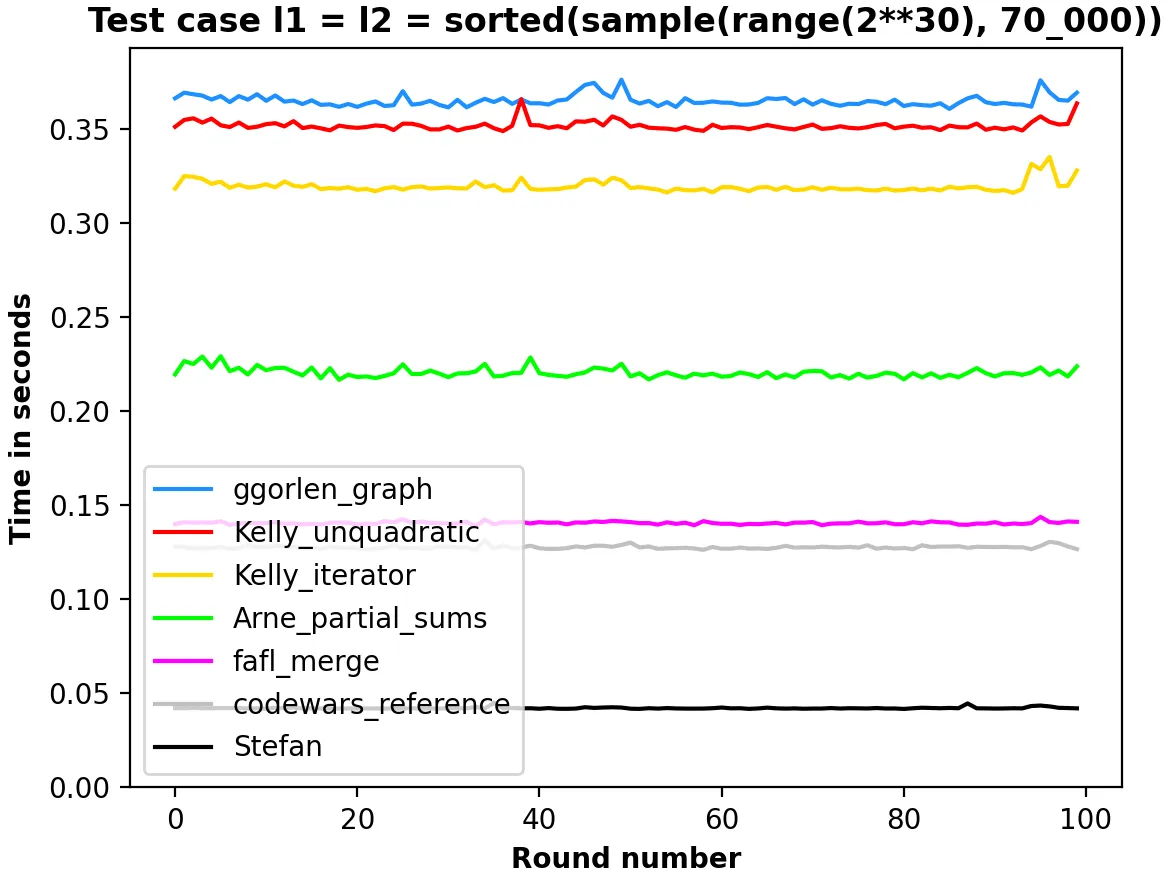
time.time来找出哪一部分占用了大部分时间。 - TheEaglestart = time.time(); #执行需要很长时间的任务; print(time.time() - start)- 你将会得到两次time.time调用之间的毫秒数。 - TheEagle你的解决方案的最大时间复杂度可以是O(len(l1) + len(l2))。不过我不知道如何获取你代码的时间复杂度...需要有其他人来做。 - TheEagle