我想要获取之前(延迟)计算出的数值?
我想要实现的是这样一个功能:
id | value
-------|-------
1 | 1
2 | 3
3 | 5
4 | 7
5 | 9
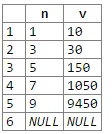
我想要实现的是这样一个功能:
id | value | new value
-------|-------|-----------
1 | 1 | 10 <-- 1 * lag(new_value)
2 | 3 | 30 <-- 3 * lag(new_value)
3 | 5 | 150 <-- 5 * lag(new_value)
4 | 7 | 1050 <-- 7 * lag(new_value)
5 | 9 | 9450 <-- 9 * lag(new_value)
我尝试过的方法:
SELECT value,
COALESCE(lag(new_value) OVER () * value, 10) AS new_value
FROM table
错误:
错误:列“new_value”不存在
{1,2,3,4,5},但之后变成了{1,3,5,7,9}? - Juan Carlos Oropezacoalesce()来配合lag函数。你可以直接将默认值传递给lag()函数:lag(some_col, 1, 0)。 - user330315