我有一张表:
MyTable
ID
FieldA
FieldB
我想修改表格并添加一列,使其看起来像:
MyTable
ID
NewField
FieldA
FieldB
在MySQL中我会这样做:
ALTER TABLE MyTable ADD COLUMN NewField int NULL AFTER ID;
一行代码,简洁明了,非常好用。我该如何在微软的世界里做到这一点?
我有一张表:
MyTable
ID
FieldA
FieldB
我想修改表格并添加一列,使其看起来像:
MyTable
ID
NewField
FieldA
FieldB
在MySQL中我会这样做:
ALTER TABLE MyTable ADD COLUMN NewField int NULL AFTER ID;
一行代码,简洁明了,非常好用。我该如何在微软的世界里做到这一点?
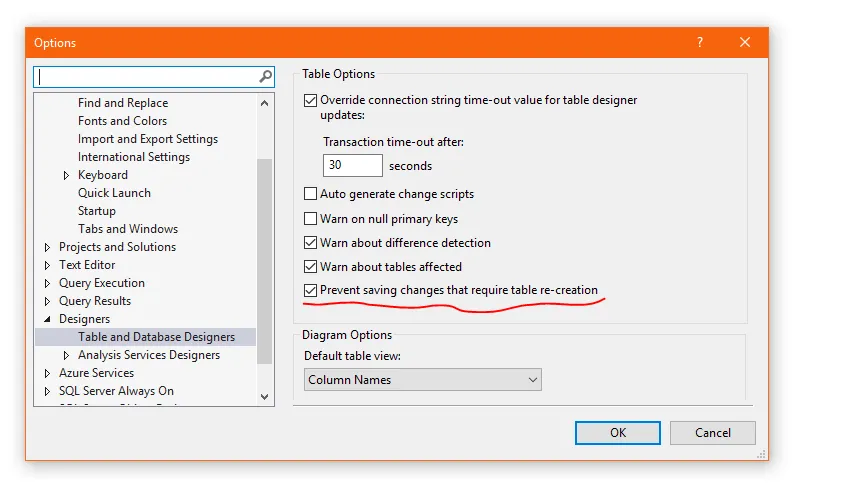
很抱歉,您不能这样做。
如果您真的希望按照那个顺序进行排序,您需要创建一个新表,并按照该顺序添加列并复制数据。或者重命名列等。没有简单的方法。
对于没有依赖于正在更改的表格,导致级联事件触发的情况,此方法可行。 首先确保您可以删除要重构的表格而不会造成任何灾难性后果。记录与您的表格相关的所有依赖项和列约束(即触发器、索引等)。完成后,您可能需要将它们放回去。
步骤1:创建临时表以保存要重构的表中的所有记录。不要忘记包括新列。
CREATE TABLE #tmp_myTable
( [new_column] [int] NOT NULL, <-- new column has been inserted here!
[idx] [bigint] NOT NULL,
[name] [nvarchar](30) NOT NULL,
[active] [bit] NOT NULL
)
步骤2: 确保所有记录都已复制过来,并且列结构看起来符合您的要求。
SELECT TOP 10 * FROM #tmp_myTable ORDER BY 1 DESC
-- 您可以执行 COUNT(*) 或任何其他操作,以确保已复制所有记录
步骤3: 删除原始表:
DROP TABLE myTable
如果您担心可能会发生意外情况,请将原始表重命名(而不是删除它)。 这样可以随时恢复。
EXEC sp_rename myTable, myTable_Copy
步骤4:按照需要重新创建表myTable(应与#tmp_myTable表结构匹配)。
CREATE TABLE myTable
( [new_column] [int] NOT NULL,
[idx] [bigint] NOT NULL,
[name] [nvarchar](30) NOT NULL,
[active] [bit] NOT NULL
)
-- 不要忘记任何你可能需要的约束条件
步骤5:将临时表#tmp_myTable中的所有记录复制到新的(改进后的)表myTable中。
INSERT INTO myTable ([new_column],[idx],[name],[active])
SELECT [new_column],[idx],[name],[active]
FROM #tmp_myTable
第6步:检查所有数据是否已经回到你的新的、改进后的表 myTable 中。如果是,请清理干净并删除临时表 #tmp_myTable 和 myTable_Copy 表(如果你选择重命名而不是删除它)。
/* 用于更改表格列顺序的脚本
注意:这将创建一个新表格来替换原始表格。
警告:原始表格可能会被删除。
但是它不会复制触发器或其他表属性,只复制数据
*/
按照所需顺序生成一个新表格的列
Select Column2, Column1, Column3 Into NewTable from OldTable
删除原始表格
Drop Table OldTable;
重命名新表格
EXEC sp_rename 'NewTable', 'OldTable';
USE [master]
GO
/****** Object: StoredProcedure [SP_Set].[TrasferDataAtColumnLevel] Script Date: 8/27/2014 2:59:30 PM ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE PROCEDURE [SP_Set].[TrasferDataAtColumnLevel]
(
@database varchar(100),
@table varchar(100),
@column varchar(100),
@position int,
@datatype varchar(20)
)
AS
BEGIN
set nocount on
exec ('
declare @oldC varchar(200), @oldCDataType varchar(200), @oldCLen int,@oldCPos int
create table Test ( dummy int)
declare @columns varchar(max) = ''''
declare @columnVars varchar(max) = ''''
declare @columnsDecl varchar(max) = ''''
declare @printVars varchar(max) = ''''
DECLARE MY_CURSOR CURSOR LOCAL STATIC READ_ONLY FORWARD_ONLY FOR
select column_name, data_type, character_maximum_length, ORDINAL_POSITION from ' + @database + '.INFORMATION_SCHEMA.COLUMNS where table_name = ''' + @table + '''
OPEN MY_CURSOR FETCH NEXT FROM MY_CURSOR INTO @oldC, @oldCDataType, @oldCLen, @oldCPos WHILE @@FETCH_STATUS = 0 BEGIN
if(@oldCPos = ' + @position + ')
begin
exec(''alter table Test add [' + @column + '] ' + @datatype + ' null'')
end
if(@oldCDataType != ''timestamp'')
begin
set @columns += @oldC + '' , ''
set @columnVars += ''@'' + @oldC + '' , ''
if(@oldCLen is null)
begin
if(@oldCDataType != ''uniqueidentifier'')
begin
set @printVars += '' print convert('' + @oldCDataType + '',@'' + @oldC + '')''
set @columnsDecl += ''@'' + @oldC + '' '' + @oldCDataType + '', ''
exec(''alter table Test add ['' + @oldC + ''] '' + @oldCDataType + '' null'')
end
else
begin
set @printVars += '' print convert(varchar(50),@'' + @oldC + '')''
set @columnsDecl += ''@'' + @oldC + '' '' + @oldCDataType + '', ''
exec(''alter table Test add ['' + @oldC + ''] '' + @oldCDataType + '' null'')
end
end
else
begin
if(@oldCLen < 0)
begin
set @oldCLen = 4000
end
set @printVars += '' print @'' + @oldC
set @columnsDecl += ''@'' + @oldC + '' '' + @oldCDataType + ''('' + convert(character,@oldCLen) + '') , ''
exec(''alter table Test add ['' + @oldC + ''] '' + @oldCDataType + ''('' + @oldCLen + '') null'')
end
end
if exists (select column_name from INFORMATION_SCHEMA.COLUMNS where table_name = ''Test'' and column_name = ''dummy'')
begin
alter table Test drop column dummy
end
FETCH NEXT FROM MY_CURSOR INTO @oldC, @oldCDataType, @oldCLen, @oldCPos END CLOSE MY_CURSOR DEALLOCATE MY_CURSOR
set @columns = reverse(substring(reverse(@columns), charindex('','',reverse(@columns)) +1, len(@columns)))
set @columnVars = reverse(substring(reverse(@columnVars), charindex('','',reverse(@columnVars)) +1, len(@columnVars)))
set @columnsDecl = reverse(substring(reverse(@columnsDecl), charindex('','',reverse(@columnsDecl)) +1, len(@columnsDecl)))
set @columns = replace(replace(REPLACE(@columns, '' '', ''''), char(9) + char(9),'' ''), char(9), '''')
set @columnVars = replace(replace(REPLACE(@columnVars, '' '', ''''), char(9) + char(9),'' ''), char(9), '''')
set @columnsDecl = replace(replace(REPLACE(@columnsDecl, '' '', ''''), char(9) + char(9),'' ''),char(9), '''')
set @printVars = REVERSE(substring(reverse(@printVars), charindex(''+'',reverse(@printVars))+1, len(@printVars)))
create table query (id int identity(1,1), string varchar(max))
insert into query values (''declare '' + @columnsDecl + ''
DECLARE MY_CURSOR CURSOR LOCAL STATIC READ_ONLY FORWARD_ONLY FOR '')
insert into query values (''select '' + @columns + '' from ' + @database + '._.' + @table + ''')
insert into query values (''OPEN MY_CURSOR FETCH NEXT FROM MY_CURSOR INTO '' + @columnVars + '' WHILE @@FETCH_STATUS = 0 BEGIN '')
insert into query values (@printVars )
insert into query values ( '' insert into Test ('')
insert into query values (@columns)
insert into query values ( '') values ( '' + @columnVars + '')'')
insert into query values (''FETCH NEXT FROM MY_CURSOR INTO '' + @columnVars + '' END CLOSE MY_CURSOR DEALLOCATE MY_CURSOR'')
declare @path varchar(100) = ''C:\query.sql''
declare @query varchar(500) = ''bcp "select string from query order by id" queryout '' + @path + '' -t, -c -S '' + @@servername + '' -T''
exec master..xp_cmdshell @query
set @query = ''sqlcmd -S '' + @@servername + '' -i '' + @path
EXEC xp_cmdshell @query
set @query = ''del '' + @path
exec xp_cmdshell @query
drop table ' + @database + '._.' + @table + '
select * into ' + @database + '._.' + @table + ' from Test
drop table query
drop table Test ')
END
-- 1. Create New Add new Column Table Script
CREATE TABLE newTable
( [new_column] [int] NOT NULL, <-- new column has been inserted here!
[idx] [bigint] NOT NULL,
[name] [nvarchar](30) NOT NULL,
[active] [bit] NOT NULL
)
-- 2. COPY old table data to new table:
INSERT INTO newTable ([new_column],[idx],[name],[active])
SELECT [new_column],[idx],[name],[active]
FROM oldTable
-- 3. Check records old and new are the same:
select sum(cnt) FROM (
SELECT 'table_1' AS table_name, COUNT(*) cnt FROM newTable
UNION
SELECT 'table_2' AS table_name, -COUNT(*) cnt FROM oldTable
) AS cnt_sum
-- 4. DROP old table
DROP TABLE oldTable
-- 5. rename newtable to oldtable
USE [DB_NAME]
EXEC sp_rename newTable, oldTable