简短回答:通常情况下,str 切片会复制数据。这意味着对于每个字符串的 n 个后缀进行切片的函数会执行 O(n2) 次操作。不过,如果你能使用类似于 bytes 的对象,并使用 memoryview 来获取原始字节数据的零拷贝视图,就可以避免复制。请查看下面的如何进行零拷贝切片以了解如何实现。
详细回答:(C)Python 中的 str 不会通过引用数据子集的视图进行切片。就 str 切片而言,有三种操作模式:
- 完整切片,例如
mystr[:] :返回到确切相同的 str 的引用(不仅是共享数据,而是同一对象,mystr is mystr [:],因为 str 是不可变的,所以这样做没有风险)
- 零长度切片和(依赖于实现)缓存长度为1的切片;空字符串是单例的(
mystr[1:1] is mystr[2:2] is ''),长度为1的低序字符串也是缓存单例的(在CPython3.5.0上,所有可以表示的字符集latin-1即Unicode取值在 range(256) 范围内的字符都被缓存了)
- 其他所有切片:创建时会复制被切割的
str,并且此后与原始 str 无关
为什么 #3 是一般规则?主要是为了避免通过小部分数据的视图来保留大型 str 的问题。如果你有一个1GB的文件,读入并像这样进行切片(是的,当你可以寻址时,这是浪费的,这只是为了说明):
with open(myfile) as f:
data = f.read()[-1024:]
如果你使用视图来展示最终1 KB的数据,那么你需要在内存中保存1 GB的数据,这是非常浪费的。由于切片通常较小,复制一个切片通常比创建视图更快。这也意味着 str 可以更简单;它需要知道自己的大小,但不需要跟踪数据的偏移量。
如何进行零拷贝切片
有一些方法可以在 Python 中执行基于视图的切片,在 Python 2 中可以对 str 进行操作(因为在 Python 2 中,str 是类似字节的数据类型,支持缓冲区协议)。在 Py2 str 和 Py3 bytes(以及许多其他数据类型,如 bytearray、array.array、numpy 数组、mmap.mmap 等),你可以创建一个memoryview,这是原始对象的零拷贝视图,可以进行切片而不复制数据。因此,如果您可以使用(或编码)到 Py2 str/Py3 bytes,并且您的函数可以处理任意的类似字节的对象,那么你可以这样做:
def do_something_on_all_suffixes(big_string):
# In Py3, may need to encode as latin-1 or the like
remaining_suffix = memoryview(big_string)
# Rather than explicit loop, just replace view with one shorter view
# on each loop
while remaining_suffix: # Stop when we've sliced to empty view
some_constant_time_operation(remaining_suffix)
remaining_suffix = remaining_suffix[1:]
memoryview的切片确实会创建新的视图对象(它们非常轻量级,与所查看的数据量无关),但并不包含任何数据,因此some_constant_time_operation可以在需要时存储副本,而在后面对其进行切片时不会更改。如果你需要一个像Py2中的str/Py3中的bytes一样的完整副本,可以调用.tobytes()以获取原始的bytes对象,或者(仅在Py3中可行)直接将其解码为一个str,该字符串从缓冲区复制,例如:str(remaining_suffix[10:20], 'latin-1')。
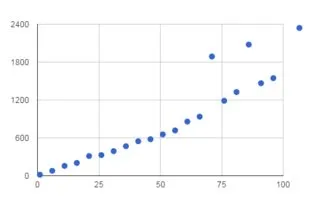
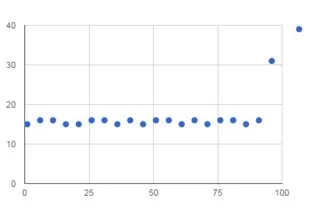
n的字符串,它保证了复杂度为O(n)。 - Yannis P.sorted(xrange(n), key=lambda i: buffer(data, i))用于创建后缀数组 - jfs