我正在阅读这个问题,它描述了以下问题陈述:
给定两个整数:N和K。Lun狗对满足以下条件的字符串感兴趣:
- 字符串恰好有N个字符,每个字符都是'A'或'B'。 - 字符串s恰好有K个对(i,j) (0 <= i < j <= N-1),使得s[i]='A'且s[j]='B'。
如果存在满足条件的字符串,则找到并返回任何一个这样的字符串。否则,返回一个空字符串
我想到这个问题等价于:
确定是否存在任何2分区0...N-1,其中笛卡尔积包含恰好K个元组(i,j),其中i其中,元组元素表示将字符串索引分配给字符
这会产生非常朴素(但正确)的实现:
您可以在这里的原始问题上下文中测试结果。一些
显然,如果我们只需要一个满足要求的单个划分(这就是原问题所要求的),并且进行所有计算时都懒惰地进行,通常情况下我们不会进入最坏情况。但是总体而言,这种方法似乎仍然非常浪费,因为我们计算的大多数分区从未满足具有
我的问题是是否有一些进一步的抽象或同构可以被识别出来以使其更加高效。例如,是否可能构造一个2-分区的子集,以便笛卡尔积上的条件在构造时得到满足?
给定两个整数:N和K。Lun狗对满足以下条件的字符串感兴趣:
- 字符串恰好有N个字符,每个字符都是'A'或'B'。 - 字符串s恰好有K个对(i,j) (0 <= i < j <= N-1),使得s[i]='A'且s[j]='B'。
如果存在满足条件的字符串,则找到并返回任何一个这样的字符串。否则,返回一个空字符串
我想到这个问题等价于:
确定是否存在任何2分区0...N-1,其中笛卡尔积包含恰好K个元组(i,j),其中i其中,元组元素表示将字符串索引分配给字符
A和B。
这会产生非常朴素(但正确)的实现:
- 确定集合
0...N-1的所有2部分划分 - 对于每个这样的划分,生成子集的笛卡尔积
- 对于每个笛卡尔积,计算元组
(i, j)的数量,其中i < j - 选择任何此计数为
K的2部分划分
const test = ([l, r]) =>
cart(l, r).reduce((p, [li, ri]) => p + (li < ri ? 1 : 0), 0) === k
const indices = _.range(0, n)
const results = partitions(indices).filter(test)
您可以在这里的原始问题上下文中测试结果。一些
n = 13,k = 29的示例输出:"aababbbbbbbbb", "babaaabbbbbbb", "baabababbbbbb", "abbaababbbbbb", ...
仅仅第一步的复杂度就是将集合划分的方法数:这是非常困难的第二类斯特林数 S(n, k),其中k = 2:
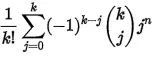
n=13,结果为4095,这并不理想。显然,如果我们只需要一个满足要求的单个划分(这就是原问题所要求的),并且进行所有计算时都懒惰地进行,通常情况下我们不会进入最坏情况。但是总体而言,这种方法似乎仍然非常浪费,因为我们计算的大多数分区从未满足具有
i<j的笛卡尔积中的k元组的属性。我的问题是是否有一些进一步的抽象或同构可以被识别出来以使其更加高效。例如,是否可能构造一个2-分区的子集,以便笛卡尔积上的条件在构造时得到满足?
