Description
不使用分割字符串的方法,可以考虑直接匹配并处理所有找到的匹配项。
此表达式将:
- 按逗号分隔您的样本文本
- 处理空值
- 忽略双引号中的逗号,只要双引号没有嵌套即可
- 从返回的值中修剪定界逗号
- 从返回的值中修剪周围的引号
- 如果字符串以逗号开头,则第一个捕获组将返回一个null值
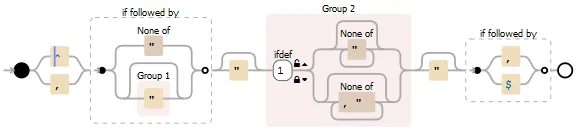
正则表达式:(?:^|,)(?=[^"]|(")?)"?((?(1)[^"]*|[^,"]*))"?(?=,|$)
Example
示例文本
123,2.99,AMO024,Title,"Description, more info",,123987564
使用非Java表达式的ASP示例
Set regEx = New RegExp
regEx.Global = True
regEx.IgnoreCase = True
regEx.MultiLine = True
sourcestring = "your source string"
regEx.Pattern = "(?:^|,)(?=[^""]|("")?)""?((?(1)[^""]*|[^,""]*))""?(?=,|$)"
Set Matches = regEx.Execute(sourcestring)
For z = 0 to Matches.Count-1
results = results & "Matches(" & z & ") = " & chr(34) & Server.HTMLEncode(Matches(z)) & chr(34) & chr(13)
For zz = 0 to Matches(z).SubMatches.Count-1
results = results & "Matches(" & z & ").SubMatches(" & zz & ") = " & chr(34) & Server.HTMLEncode(Matches(z).SubMatches(zz)) & chr(34) & chr(13)
next
results=Left(results,Len(results)-1) & chr(13)
next
Response.Write "<pre>" & results
使用非 Java 表达式进行匹配
Group 0 获取包括逗号在内的整个子字符串
Group 1 获取引号(如果有)
Group 2 获取不包括逗号的值
[0][0] = 123
[0][1] =
[0][2] = 123
[1][0] = ,2.99
[1][1] =
[1][2] = 2.99
[2][0] = ,AMO024
[2][1] =
[2][2] = AMO024
[3][0] = ,Title
[3][1] =
[3][2] = Title
[4][0] = ,"Description, more info"
[4][1] = "
[4][2] = Description, more info
[5][0] = ,
[5][1] =
[5][2] =
[6][0] = ,123987564
[6][1] =
[6][2] = 123987564
编辑
正如Boris指出的,CSV格式将把双引号"转义为双倍双引号""。虽然这不是原帖中提到的要求,但如果您的文本包含双倍双引号,则需要使用这个修改后的表达式:
正则表达式:(?:^|,)(?=[^"]|(")?)"?((?(1)(?:[^"]|"")*|[^,"]*))"?(?=,|$)
另请参阅:https://regex101.com/r/y8Ayag/1
还应指出,正则表达式是一种模式匹配工具,而不是解析引擎。因此,如果您的文本包含双倍双引号,则在模式匹配完成后仍将包含双倍双引号。使用这个解决方案后,您仍需要搜索双倍双引号并替换捕获的文本中的它们。

a "b" c最终将以CSV格式呈现为"a ""b"" c"。任何优秀的CSV解析器都需要能够处理这种情况。 - Thomas Tempelmann