我在PostgreSQL中有一个包裹表,其中分区和分区说明列是array_agg转换为文本。新的universities表有9行,我需要在输出中返回9行。
该查询的目的是查找所有这些大学所在的属性,并将其分区类型合并为1个唯一的列,并将它们的几何图形合并/溶解为多边形。
我遇到了这个错误。
该查询的目的是查找所有这些大学所在的属性,并将其分区类型合并为1个唯一的列,并将它们的几何图形合并/溶解为多边形。
select array_agg(distinct dp.zoning) zoning,array_agg(distinct dp.zoning_description) zoning_description,
uni.school name_,uni.address,'University' type_,1000 buff,st_union(dp.geom)
from new.universities uni join new.detroit_parcels_update dp
on st_intersects(st_buffer(uni.geom,-10),dp.geom)
group by name_,uni.address,type_,buff
我遇到了这个错误。
ERROR: cannot accumulate arrays of different dimensionality
********** Error **********
ERROR: cannot accumulate arrays of different dimensionality
SQL state: 2202E
我可以使用array_agg(distinct dp.zoning::text) zoning等方法,但这将返回一个完全混乱的列,其中包含嵌套的数组...

根据此答案,这是我的更新查询,但它不起作用。
select array_agg(distinct zoning_u) zoning,array_agg(distinct zoning_description_u) zoning_description,
uni.school name_,uni.address,'University' type_,1000::int buff,st_union(dp.geom) geom
from new.detroit_parcels_update dp,unnest(zoning) zoning_u,
unnest(zoning_description) zoning_description_u
join new.universities uni
on st_intersects(st_buffer(uni.geom,-10),dp.geom)
group by name_,uni.address,type_,buff order by name_
遇到此错误
ERROR: invalid reference to FROM-clause entry for table "dp"
LINE 6: on st_intersects(st_buffer(uni.geom,-10),dp.geom)
^
HINT: There is an entry for table "dp", but it cannot be referenced from this part of the query.
********** Error **********
ERROR: invalid reference to FROM-clause entry for table "dp"
SQL state: 42P01
Hint: There is an entry for table "dp", but it cannot be referenced from this part of the query.
Character: 373
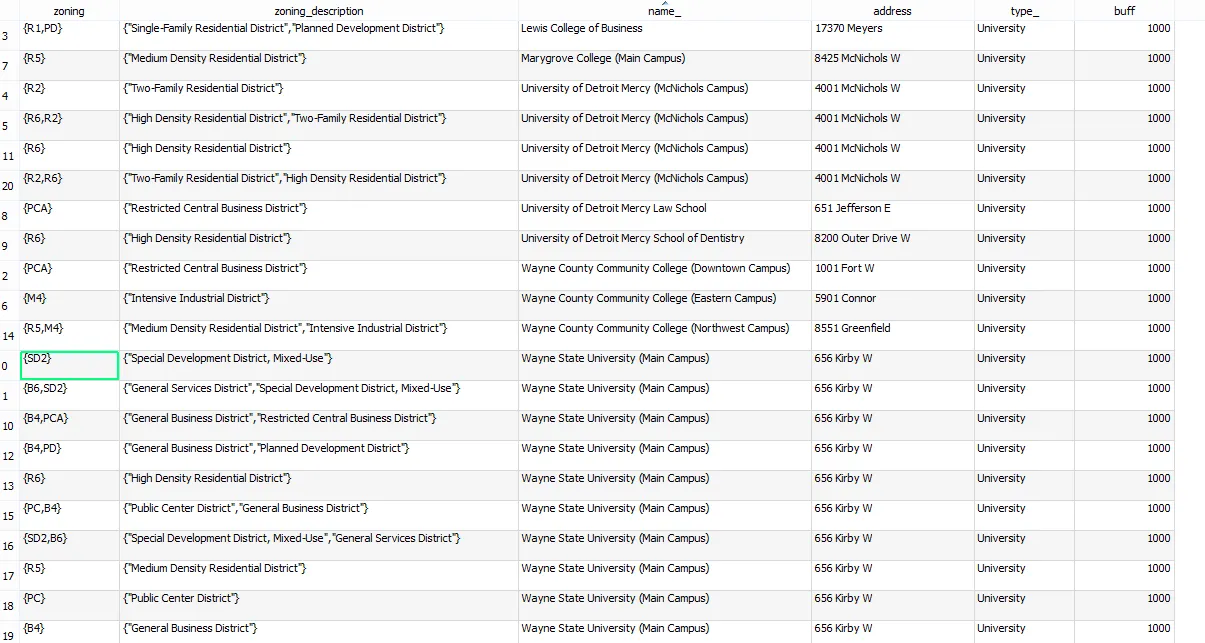
我的最终查询是这样的
with t as(select dp.zoning,dp.zoning_description,uni.school name_,uni.address,'University' type_,1000::int buff,st_union(dp.geom) geom
from new.detroit_parcels_update dp
join new.universities uni
on st_intersects(st_buffer(uni.geom,-10),dp.geom)
group by name_,uni.address,type_,buff,dp.zoning,zoning_description order by name_
)
select name_,address,type_,buff,st_union(geom) geom,array_agg(distinct z) zoning, array_agg(distinct zd) zoning_description
from t,unnest(zoning) z,unnest(zoning_description) zd
group by name_,address,type_,buff
< my_table, unnest(numbers) as number, unnest(letters) as letter >。 - ziggy