我正在使用pyspark的LDAModel从语料库中获取主题。我的目标是找到与每个文档相关的主题。为此,我尝试根据文档设置topicDistributionCol。由于我是新手,我不确定这列的目的是什么。
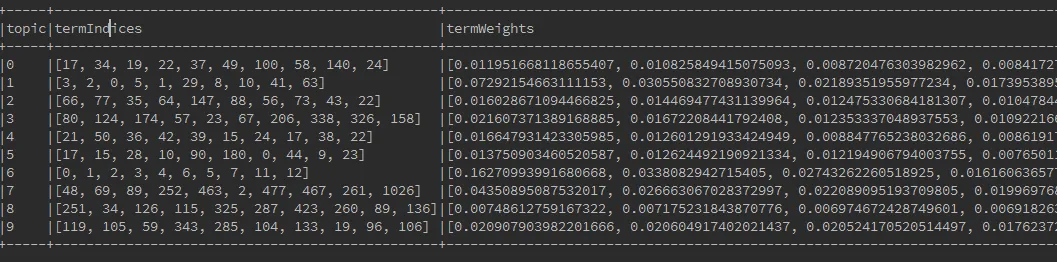
它列出了所有主题及其术语索引和术语权重。
注意:我之前使用gensim的LDA模型完成了这个任务,使用以下代码。但是我现在需要使用pyspark的LDA模型。
from pyspark.ml.clustering import LDA
lda_model = LDA(k=10, optimizer="em").setTopicDistributionCol("topicDistributionCol")
// documents is valid dataset for this lda model
lda_model = lda_model.fit(documents)
transformed = lda_model.transform(documents)
topics = lda_model.describeTopics(maxTermsPerTopic=num_words_per_topic)
print("The topics described by their top-weighted terms:")
print topics.show(truncate=False)
它列出了所有主题及其术语索引和术语权重。
print transformed.select("topicDistributionCol").show(truncate=False)

doc | topic
1 | [2,4]
2 | [3,4,6]
注意:我之前使用gensim的LDA模型完成了这个任务,使用以下代码。但是我现在需要使用pyspark的LDA模型。
texts = [[word for word in document.lower().split() if word not in stoplist] for document in documents]
dictionary = corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
doc_topics = LdaModel(corpus=corpus, id2word=dictionary, num_topics=10, passes=10)
## to fetch topics for one document
vec_bow = dictionary.doc2bow(text[0])
Topics = doc_topics[vec_bow]
Topic_list = [x[0] for x in Topics]
## topic list is [1,5]