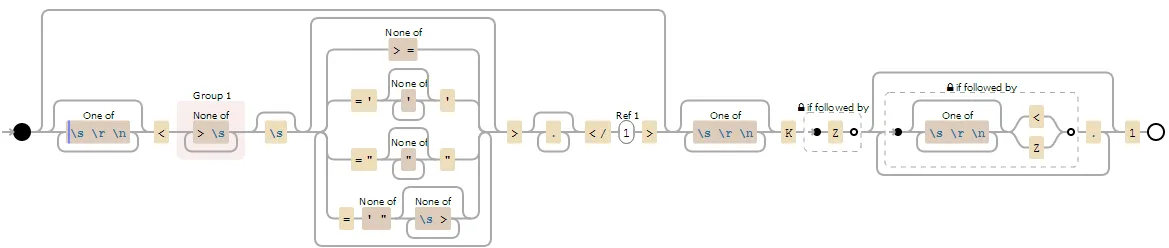
这是一个关于正则表达式的问题。
如果我有一系列XML节点,我想要使用正则表达式解析出与我的当前节点在同一级别的包含节点值。例如,如果我有以下内容:
我想检索一个数组,该数组为:
我知道我可以从以下内容开始:
并且这将检索出文本,但不包括
编辑:实际上,那个preg_match似乎只在
注意:我感谢并将遵守任何澄清请求;但是,我的问题非常具体,我的意思是我在问什么,所以不要给出像“去使用SimpleXML”之类的答案。谢谢您的所有帮助。
如果我有一系列XML节点,我想要使用正则表达式解析出与我的当前节点在同一级别的包含节点值。例如,如果我有以下内容:
<top-node>
Hi
<second-node>
Hello
<inner-node>
</inner-node>
</second-node>
Hey
<third-node>
Foo
</third-node>
Bar
<top-node>
我想检索一个数组,该数组为:
array(
1 => 'Hi',
2 => 'Hey',
3 => 'Bar'
)
我知道我可以从以下内容开始:
$inside = preg_match('~<(\S+).*?>(?P<inside>(.|\s)*)</\1>~', $original_text);
并且这将检索出文本,但不包括
顶级节点。然而,下一步有点超出我的正则表达式能力。编辑:实际上,那个preg_match似乎只在
$original_text都在同一行时才工作。此外,我认为我可以使用一个非常类似的正则表达式的preg_split来检索我要查找的内容-它只是在多行上没有起作用。注意:我感谢并将遵守任何澄清请求;但是,我的问题非常具体,我的意思是我在问什么,所以不要给出像“去使用SimpleXML”之类的答案。谢谢您的所有帮助。