这个错误非常明显。它表示对于超过2个类别的问题,需要有某种平均规则。有效的规则包括:'micro'、'macro'、'weighted'和None(文档列出了'samples',但不适用于多类目标)。
如果我们看一下源代码,在精度和召回率计算方面,多类问题被视为多标签问题,因为使用的基础混淆矩阵(multilabel_confusion_matrix)是相同的。1 这个混淆矩阵创建一个3D数组,其中每个“子矩阵”都是2x2的混淆矩阵,其中正值是标签之一。
每种平均规则之间有什么区别?
当average=None时,将返回每个类别的精确度/召回率分数(没有任何平均值),因此我们得到一个分数数组,其长度等于类别数量。2
当average='macro'时,会计算每个类别的精确度/召回率,然后取平均值。其公式如下:

当average='micro'时,将累加所有类别的贡献来计算平均精确度/召回率。其公式如下:
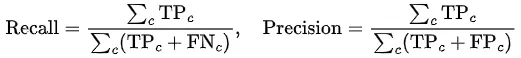
average='weighted'实际上是带权重的宏平均,其中权重为实际正类。其公式如下:

让我们考虑一个例子。
import numpy as np
from sklearn import metrics
y_true, y_pred = np.random.default_rng(0).choice(list('abc'), size=(2,100), p=[.8,.1,.1])
mcm = metrics.multilabel_confusion_matrix(y_true, y_pred)
上面计算出的多标签混淆矩阵如下所示。
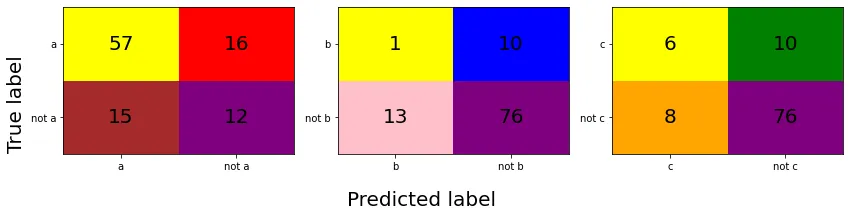
相应的精确度/召回率得分如下:
average='macro' 的精确率/召回率为:
recall_macro = (57 / (57 + 16) + 1 / (1 + 10) + 6 / (6 + 10)) / 3
precision_macro = (57 / (57 + 15) + 1 / (1 + 13) + 6 / (6 + 8)) / 3
recall_macro == metrics.recall_score(y_true, y_pred, average='macro')
precision_macro == metrics.precision_score(y_true, y_pred, average='macro')
average='micro' 的精确率/召回率为:
recall_micro = (57 + 1 + 6) / (57 + 16 + 1 + 10 + 6 + 10)
precision_micro = (57 + 1 + 6) / (57 + 15 + 1 + 13 + 6 + 8)
recall_micro == metrics.recall_score(y_true, y_pred, average='micro')
precision_micro == metrics.precision_score(y_true, y_pred, average='micro')
average='weighted' 的精确率/召回率为:
recall_weighted = (57 / (57 + 16) * (57 + 16) + 1 / (1 + 10) * (1 + 10) + 6 / (6 + 10) * (6 + 10)) / (57 + 16 + 1 + 10 + 6 + 10)
precision_weighted = (57 / (57 + 15) * (57 + 16) + 1 / (1 + 13) * (1 + 10) + 6 / (6 + 8) * (6 + 10)) / (57 + 16 + 1 + 10 + 6 + 10)
recall_weighted == metrics.recall_score(y_true, y_pred, average='weighted')
precision_weighted == metrics.precision_score(y_true, y_pred, average='weighted')
正如你所看到的,这个例子是不平衡的(类别a的频率为80%,而b和c每个都为10%)。平均规则之间的主要区别在于'macro'平均不考虑类别的不平衡,而'micro'和'weighted'则考虑。因此,'macro'对类别的不平衡比较敏感,可能会导致得分过高或过低,具体取决于不平衡的情况。
此外,从公式可以很容易地看出,'micro'和'weighted'的召回率相等。
为什么average='micro'时准确率==召回率==精确度==F1得分?
用视觉方式理解可能更容易。
如果我们看一下上面构建的多标签混淆矩阵,每个子矩阵对应于一个One vs Rest分类问题;即在子矩阵的非列/行中,另外两个标签已经计入。
例如,对于第一个子矩阵,有
- 57个真正例(
a)
- 16个假负例(
b或c)
- 15个假正例(
b或c)
- 12个真负例
对于精度/召回率的计算,只有TP、FN和FP才有意义。如上所述,FN和FP计数可以是b或c中的任何一个;由于它是二进制的,因此这个子矩阵本身无法说明预测了多少个每个类别;但是,我们可以通过调用confusion_matrix()方法来计算多类混淆矩阵,从而确定每个类别被正确分类的数量。
mccm = metrics.confusion_matrix(y_true, y_pred)
下图绘制了相同的混淆矩阵(
mccm),但使用不同的背景颜色进行区分(黄色背景对应于TP,第一个子矩阵中的红色背景对应于假阴性,橙色对应于第三个子矩阵中的假阳性等)。因此,这些实际上是多标签混淆矩阵中的TP、FN和FP“扩展”到考虑负类别的情况。左图的颜色方案与多标签混淆矩阵中TP和FN计数的颜色相匹配(用于确定
召回率),右图的颜色方案则与TP和FP的颜色相匹配(用于确定
精确度)。
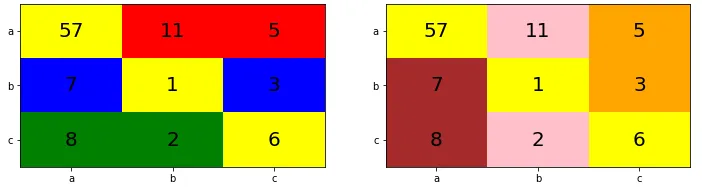
使用 average='micro',左侧图表中黄色背景数字与所有数字的比率确定了召回率,右侧图表中黄色背景数字与所有数字的比率确定了精确度。如果我们仔细观察,相同的比率也确定了准确度。此外,由于f1得分是精确度和召回率的调和平均值,并且它们相等,因此我们有关系式recall == precision == accuracy == f1-score。