在Python中,最有效的旋转列表的方式是什么? 目前我有类似以下代码:
>>> def rotate(l, n):
... return l[n:] + l[:n]
...
>>> l = [1,2,3,4]
>>> rotate(l,1)
[2, 3, 4, 1]
>>> rotate(l,2)
[3, 4, 1, 2]
>>> rotate(l,0)
[1, 2, 3, 4]
>>> rotate(l,-1)
[4, 1, 2, 3]
有更好的方法吗?
collections.deque是为了从两端进行推入和弹出而进行优化的。它们甚至有一个专门的rotate()方法。
from collections import deque
items = deque([1, 2])
items.append(3) # deque == [1, 2, 3]
items.rotate(1) # The deque is now: [3, 1, 2]
items.rotate(-1) # Returns deque to original state: [1, 2, 3]
item = items.popleft() # deque == [2, 3]
rotate() 操作比切片更快。 - Geoffdeque.rotate需要先将列表转换为deque对象,这比l.append(l.pop(0))慢。因此,如果你一开始就有一个deque对象,那么使用它是最快的。否则,使用l.append(l.pop(0))。 - Purrelldeque.rotate 的时间复杂度为 O(k),但是从列表转换到双向队列的类型转换时间复杂度为 O(n)。因此,如果你从一个列表开始,使用 deque.rotate 的时间复杂度为 O(n)+O(k)=O(n)。另一方面,l.append(l.pop(0)) 的时间复杂度为 O(1)。 - Purrell那么只使用 pop(0) 怎么样?
list.pop([i])移除列表中给定位置的元素,并返回该元素。如果没有指定索引,
a.pop()则会移除并返回列表中的最后一个元素。(在方法签名中方括号内的i表示该参数是可选的,而不是你应该在该位置输入方括号。你将经常在Python库参考手册中看到这种记法。)
l.append(l.pop(0))。如果我没有错的话,时间复杂度为O(1)。 - PurrellNumpy可以使用roll命令来实现这一点:
>>> import numpy
>>> a=numpy.arange(1,10) #Generate some data
>>> numpy.roll(a,1)
array([9, 1, 2, 3, 4, 5, 6, 7, 8])
>>> numpy.roll(a,-1)
array([2, 3, 4, 5, 6, 7, 8, 9, 1])
>>> numpy.roll(a,5)
array([5, 6, 7, 8, 9, 1, 2, 3, 4])
>>> numpy.roll(a,9)
array([1, 2, 3, 4, 5, 6, 7, 8, 9])
这取决于你希望当你这样做时发生什么:
>>> shift([1,2,3], 14)
def shift(seq, n):
return seq[n:]+seq[:n]
发送至:
def shift(seq, n):
n = n % len(seq)
return seq[n:] + seq[:n]
我能想到的最简单方法:
a.append(a.pop(0))
collections.deque 更快,但对于大多数常见情况下的单次迭代或任何多次迭代的列表长度,a.append(a.pop(0)) 比转换为 deque 更快。 - Purrell关于时间的一些注意事项:
如果你从一个列表开始,l.append(l.pop(0)) 是你可以使用的最快速的方法。这可以通过时间复杂度来证明:
deque.rotate 的时间复杂度为 O(k) (k=元素数目)append 和 pop 都是 O(1)因此,如果你从 deque 对象开始,你可以以 O(k) 的代价使用 deque.rotate()。但是,如果起点是一个列表,则使用 deque.rotate() 的时间复杂度为 O(n)。 l.append(l.pop(0) 的时间复杂度为 O(1),更快。
仅供举例,以下是 100 万次迭代的一些样本计时:
需要类型转换的方法:
deque.rotate(使用 deque 对象):0.12380790710449219 秒(最快)deque.rotate(使用类型转换):6.853878974914551 秒np.roll(使用 nparray):6.0491721630096436 秒np.roll(使用类型转换):27.558452129364014 秒这里提到的列表方法:
l.append(l.pop(0)):0.32483696937561035 秒(最快)shiftInPlace":4.819645881652832 秒用于计时的代码如下。
展示从列表创建 deque 的时间复杂度是 O(n):
from collections import deque
import big_o
def create_deque_from_list(l):
return deque(l)
best, others = big_o.big_o(create_deque_from_list, lambda n: big_o.datagen.integers(n, -100, 100))
print best
# --> Linear: time = -2.6E-05 + 1.8E-08*n
如果您需要创建双向队列对象:
1M 次迭代 @ 6.853878974914551 秒
setup_deque_rotate_with_create_deque = """
from collections import deque
import random
l = [random.random() for i in range(1000)]
"""
test_deque_rotate_with_create_deque = """
dl = deque(l)
dl.rotate(-1)
"""
timeit.timeit(test_deque_rotate_with_create_deque, setup_deque_rotate_with_create_deque)
如果您已经有了双端队列对象:
1M 次迭代 @ 0.12380790710449219 秒
setup_deque_rotate_alone = """
from collections import deque
import random
l = [random.random() for i in range(1000)]
dl = deque(l)
"""
test_deque_rotate_alone= """
dl.rotate(-1)
"""
timeit.timeit(test_deque_rotate_alone, setup_deque_rotate_alone)
如果需要创建nparrays
1M次迭代 @ 27.558452129364014 秒
setup_np_roll_with_create_npa = """
import numpy as np
import random
l = [random.random() for i in range(1000)]
"""
test_np_roll_with_create_npa = """
np.roll(l,-1) # implicit conversion of l to np.nparray
"""
如果您已经有nparrays:
1M次迭代,用时6.0491721630096436秒。
setup_np_roll_alone = """
import numpy as np
import random
l = [random.random() for i in range(1000)]
npa = np.array(l)
"""
test_roll_alone = """
np.roll(npa,-1)
"""
timeit.timeit(test_roll_alone, setup_np_roll_alone)
无需进行类型转换
1M 次迭代 @ 4.819645881652832 秒
setup_shift_in_place="""
import random
l = [random.random() for i in range(1000)]
def shiftInPlace(l, n):
n = n % len(l)
head = l[:n]
l[:n] = []
l.extend(head)
return l
"""
test_shift_in_place="""
shiftInPlace(l,-1)
"""
timeit.timeit(test_shift_in_place, setup_shift_in_place)
不需要进行类型转换
1M次迭代 @ 0.32483696937561035
setup_append_pop="""
import random
l = [random.random() for i in range(1000)]
"""
test_append_pop="""
l.append(l.pop(0))
"""
timeit.timeit(test_append_pop, setup_append_pop)
l = [random.random() for i in range(100000)]。 - emul.append(l.pop(0))在将短列表(约7个元素)向右移动一个位置时表现最佳? - Wolf我也对此产生了兴趣,并用perfplot(我的一个小项目)与一些建议的解决方案进行了比较。
结果发现,Kelly Bundy的建议
tmp = data[shift:]
tmp += data[:shift]
在所有移位中表现非常出色。
实际上,perfplot 对逐渐增大的数组执行移位操作,并测量时间。以下是结果:
shift = 1:
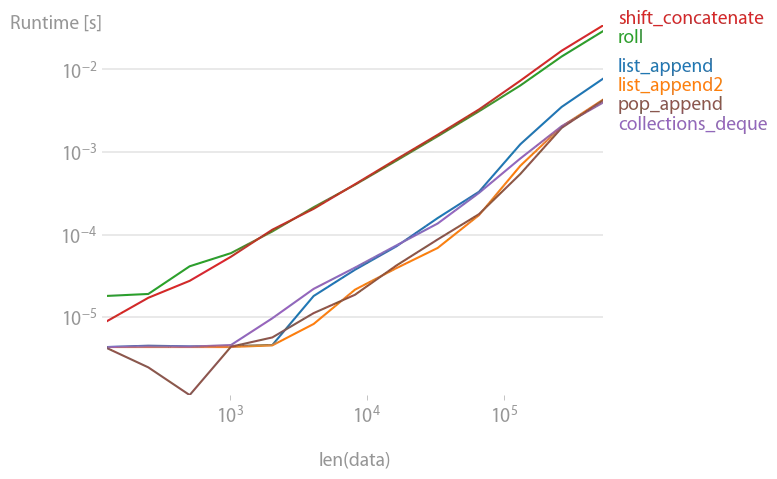
shift = 100:
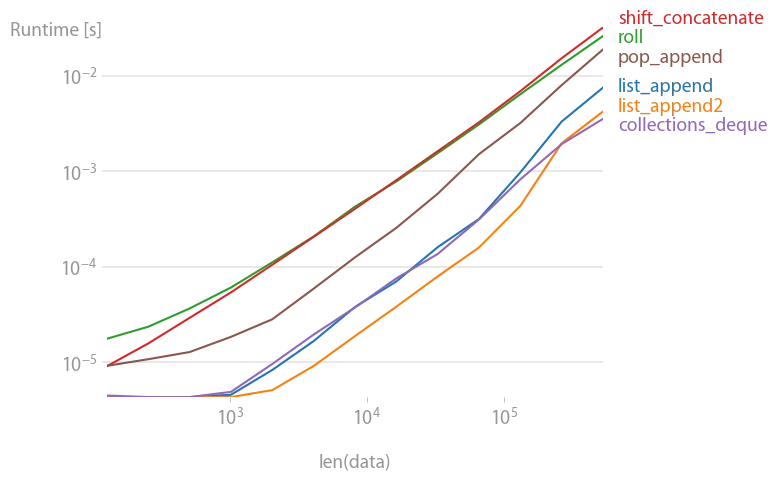
用于重现绘图的代码:
import numpy
import perfplot
import collections
shift = 100
def list_append(data):
return data[shift:] + data[:shift]
def list_append2(data):
tmp = data[shift:]
tmp += data[:shift]
return tmp
def shift_concatenate(data):
return numpy.concatenate([data[shift:], data[:shift]])
def roll(data):
return numpy.roll(data, -shift)
def collections_deque(data):
items = collections.deque(data)
items.rotate(-shift)
return items
def pop_append(data):
data = data.copy()
for _ in range(shift):
data.append(data.pop(0))
return data
b = perfplot.bench(
setup=lambda n: numpy.random.rand(n).tolist(),
kernels=[
list_append,
list_append2,
roll,
shift_concatenate,
collections_deque,
pop_append,
],
n_range=[2 ** k for k in range(7, 20)],
xlabel="len(data)",
)
b.show()
b.save("shift100.png")
def tmp_del(data): tmp = data[:shift]; del data[:shift]; data += tmp; return data(在n=1时与pop_append相匹配,在n=10时胜过它,在n=100时胜过collections_deque)。 - Kelly Bundydata.copy()和pop_append中添加了它。这对其他解决方案来说确实更公平,但现在它并没有真正意义。如果要创建一个新列表,可以使用tmp = data[shift:] tmp += data[:shift] return tmp。 - Kelly Bundylist_append的解决方案。 - Nico Schlömerlist_append 复制了 2n 个元素并丢弃了 n 个。我的代码(来自我上一条评论)只复制了 n+shft 个元素并丢弃了 shift。 - Kelly Bundy如果您只想迭代这些元素集,而不是构建单独的数据结构,请考虑使用迭代器来构造生成器表达式:
def shift(l,n):
return itertools.islice(itertools.cycle(l),n,n+len(l))
>>> list(shift([1,2,3],1))
[2, 3, 1]
这还要取决于你是想就地(改变它)移动列表,还是希望函数返回一个新列表。因为据我的测试结果,像这样的实现比添加两个列表的实现至少快二十倍:
def shiftInPlace(l, n):
n = n % len(l)
head = l[:n]
l[:n] = []
l.extend(head)
return l
实际上,即使在顶部添加l = l[:]以操作传递的列表副本,速度仍然是原来的两倍。
各种实现及其时间可以在http://gist.github.com/288272中找到。
del l[:n],而不是l[:n] = []。这只是一种不同的替代方式。 - tzotdel 在 Py3 仍然是一个语句。但是 x.__delitem__(y) <==> del x[y],因此如果您更喜欢使用方法,则 l.__delitem__(slice(n)) 也是等效的,并且在2和3中都可以使用。 - martineau如果您需要一个不可变的实现,可以使用以下方式:
def shift(seq, n):
shifted_seq = []
for i in range(len(seq)):
shifted_seq.append(seq[(i-n) % len(seq)])
return shifted_seq
print shift([1, 2, 3, 4], 1)
numpy.roll函数用于将数组沿指定轴滚动。该函数接受两个参数:a是需要滚动的数组,shift是滚动的偏移量。import numpy as np a = np.array([1, 2, 3, 4, 5]) print(np.roll(a, 2)) # [4 5 1 2 3]在上面的示例中,原始数组[1, 2, 3, 4, 5]沿着其第一个轴滚动了 2 个位置。因此,最后两个元素4和5移动到了数组开头,而前三个元素1、2和3则被推到了数组的末尾。 - BoltzmannBrain