我有一个7GB的csv文件,我想将它分成较小的块,这样在笔记本上使用Python进行分析时更易于阅读和更快。 我想从中获取一个小的集合,可能是250MB,那么我该如何做呢?
9个回答
48
您不需要使用Python来分割CSV文件。可以使用您的shell命令行:
$ split -l 100 data.csv
将data.csv文件分成每个包含100行的块。
- Thomas Orozco
4
32
我曾经需要完成一个类似的任务,使用了 pandas 库:
for i,chunk in enumerate(pd.read_csv('bigfile.csv', chunksize=500000)):
chunk.to_csv('chunk{}.csv'.format(i), index=False)
- Quentin Febvre
3
1我认为这个解决方案不好。我有一个2 Gb(16m行)的数据集,而pandas无法在内存中处理它。分块并不意味着你不需要将整个df加载到内存(RAM)中,它只是指你一次读取
chunksize指定的行数。 - Imad1这是一个很好的答案。但请注意,这将向原始CSV添加一个额外的索引列。 - Chaitanya Shivade
3这句话的意思是:这个操作会在原始的CSV文件中添加一个额外的索引列。现在通过添加Index=False已经修复了这个问题。 - brycejl
13
以下是我用的一个小Python脚本,用于将文件data.csv拆分为多个CSV部分文件。可以使用chunk_size(每个部分文件的行数)控制部分文件的数量。
原始文件的标题行(列名)将被复制到每个部分CSV文件中。
它适用于大文件,因为它使用readline()一次读取一行,而不是一次性将整个文件加载到内存中。
#!/usr/bin/env python3
def main():
chunk_size = 9998 # lines
def write_chunk(part, lines):
with open('data_part_'+ str(part) +'.csv', 'w') as f_out:
f_out.write(header)
f_out.writelines(lines)
with open('data.csv', 'r') as f:
count = 0
header = f.readline()
lines = []
for line in f:
count += 1
lines.append(line)
if count % chunk_size == 0:
write_chunk(count // chunk_size, lines)
lines = []
# write remainder
if len(lines) > 0:
write_chunk((count // chunk_size) + 1, lines)
if __name__ == '__main__':
main()
- Roberto
2
1@GooDeeJAY - 这是一个很好的答案,代码本身就很清晰易懂。优秀的代码可以“自我表达”,不需要过多的解释。 - Powers
1@Powers 我完全同意你的观点。但是,我也相信(这个社区教给了我)应该在代码上方添加一些解释性文本。我看到他已经编辑了他的帖子并添加了一些解释性文本。好像那时候我忘记了“关注”这篇文章,所以没有在他编辑帖子时收到通知,也就没删掉我的评论。 - GooDeeJAY
6
这张图展示了其他帖子提出的不同方法之间的运行时间差异(在一个8核机器上,将一个2.9GB、1180万行数据的文件分割成约290个文件时)。
我建议使用Dask来分割文件,即使它不是最快的,因为它是最灵活的解决方案(您可以编写不同的文件格式,在写入之前执行处理操作,轻松修改压缩格式等)。Pandas方法几乎同样灵活,但无法在整个数据集上执行处理(例如在写入之前对整个数据集进行排序)。
Bash /本机Python文件系统操作显然更快,但当我有一个大型CSV时,这通常不是我正在寻找的。我通常感兴趣的是将大型CSV拆分成较小的Parquet文件,以进行高效的生产数据分析。我通常不在意实际拆分需要多花费几分钟。我更关心准确拆分。
我写了一篇博客文章详细讨论了这个问题。您可以在Google上搜索并找到这篇文章。
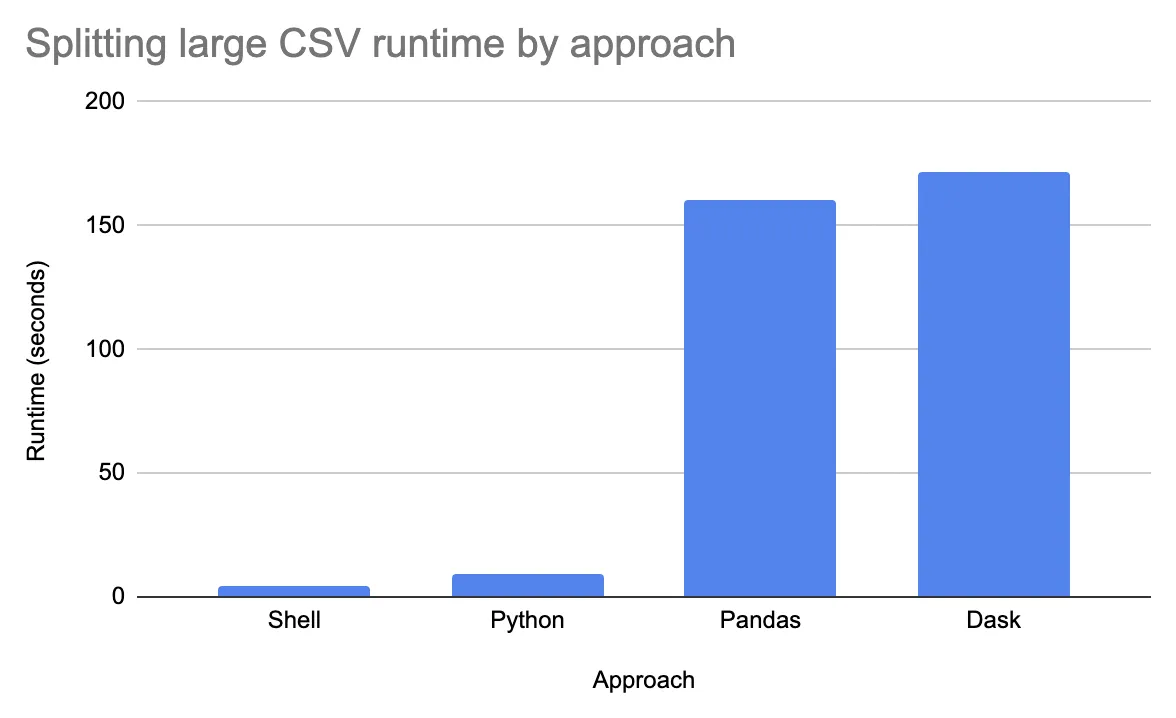
这里有四种不同的编程方法,其中Shell方法来自Thomas Orozco,Python方法来自Roberto,Pandas方法来自Quentin Febvre,以下是Dask代码片段:
ddf = dd.read_csv("../nyc-parking-tickets/Parking_Violations_Issued_-_Fiscal_Year_2015.csv", blocksize=10000000, dtype=dtypes)
ddf.to_csv("../tmp/split_csv_dask")
我建议使用Dask来分割文件,即使它不是最快的,因为它是最灵活的解决方案(您可以编写不同的文件格式,在写入之前执行处理操作,轻松修改压缩格式等)。Pandas方法几乎同样灵活,但无法在整个数据集上执行处理(例如在写入之前对整个数据集进行排序)。
Bash /本机Python文件系统操作显然更快,但当我有一个大型CSV时,这通常不是我正在寻找的。我通常感兴趣的是将大型CSV拆分成较小的Parquet文件,以进行高效的生产数据分析。我通常不在意实际拆分需要多花费几分钟。我更关心准确拆分。
我写了一篇博客文章详细讨论了这个问题。您可以在Google上搜索并找到这篇文章。
- Powers
3
也许是这样的吗?
#!/usr/local/cpython-3.3/bin/python
import csv
divisor = 10
outfileno = 1
outfile = None
with open('big.csv', 'r') as infile:
for index, row in enumerate(csv.reader(infile)):
if index % divisor == 0:
if outfile is not None:
outfile.close()
outfilename = 'big-{}.csv'.format(outfileno)
outfile = open(outfilename, 'w')
outfileno += 1
writer = csv.writer(outfile)
writer.writerow(row)
- dstromberg
1
这确实会将CSV文件拆分,但输出的CSV文件中每行之间都有空白行。 - Theo F
1
这是我的代码,可能会有所帮助
import os
import pandas as pd
import uuid
class FileSettings(object):
def __init__(self, file_name, row_size=100):
self.file_name = file_name
self.row_size = row_size
class FileSplitter(object):
def __init__(self, file_settings):
self.file_settings = file_settings
if type(self.file_settings).__name__ != "FileSettings":
raise Exception("Please pass correct instance ")
self.df = pd.read_csv(self.file_settings.file_name,
chunksize=self.file_settings.row_size)
def run(self, directory="temp"):
try:os.makedirs(directory)
except Exception as e:pass
counter = 0
while True:
try:
file_name = "{}/{}_{}_row_{}_{}.csv".format(
directory, self.file_settings.file_name.split(".")[0], counter, self.file_settings.row_size, uuid.uuid4().__str__()
)
df = next(self.df).to_csv(file_name)
counter = counter + 1
except StopIteration:
break
except Exception as e:
print("Error:",e)
break
return True
def main():
helper = FileSplitter(FileSettings(
file_name='sample1.csv',
row_size=10
))
helper.run()
main()
- Soumil Nitin Shah
2
我该如何避免在第一列出现“数字顺序列”? - DFX Nguyễn
请更改为
df = next(self.df).to_csv(file_name, index=False),以避免在第一列写入行名称(索引)。 - DFX Nguyễn1
我同意 @jonrsharpe 的观点,readline 应该能够逐行读取大文件。
如果你正在处理大型 csv 文件,我建议使用 pandas.read_csv。我经常为相同的目的使用它,并且总是发现它很棒(而且快)。需要一些时间来习惯 DataFrame 的概念。但是一旦你克服了这个问题,它就可以大大加速像你这样的大型操作。
希望这有所帮助。
- Jimmy
1
Pandas实际上是处理大型CSV文件的非常糟糕的解决方案,因为它们只能真正处理一次可以存储在RAM中的数据。建议使用其他库,如Dask。https://medium.com/analytics-vidhya/a-deep-dive-into-dask-dataframes-7455d66a5bc5 - brycejl
0
如果想按字节的粗略边界进行分割,最新的数据点在最底部,并希望将最新的数据点放在第一个文件中:
from pathlib import Path
TEN_MB = 10000000
FIVE_MB = 5000000
def split_file_into_chunks(path, chunk_size=TEN_MB):
path = str(path)
output_prefix = path.rpartition('.')[0]
output_ext = path.rpartition('.')[-1]
with open(path, 'rb') as f:
seek_positions = []
for x, line in enumerate(f):
if not x:
header = line
seek_positions.append(f.tell())
part = 0
last_seek_pos = seek_positions[-1]
for seek_pos in reversed(seek_positions):
if last_seek_pos-seek_pos >= chunk_size:
with open(f'{output_prefix}.arch.{part}.{output_ext}', 'wb') as f_out:
f.seek(seek_pos)
f_out.write(header)
f_out.write(f.read(last_seek_pos-seek_pos))
last_seek_pos = seek_pos
part += 1
with open(f'{output_prefix}.arch.{part}.{output_ext}', 'wb') as f_out:
f.seek(0)
f_out.write(f.read(last_seek_pos))
Path(path).rename(path+'~')
Path(f'{output_prefix}.arch.0.{output_ext}').rename(path)
Path(path+'~').unlink()
- user17870315
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
split -l 100 data.csv data_split_。 - Matt