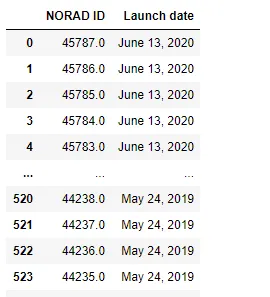
我有以下代码,试图爬取此页面上的主表格。 我需要获取第二列和第四列的NORAD ID和发射日期。 但是我无法通过ID找到该表格。
import requests
from bs4 import BeautifulSoup
data = []
URL = 'https://www.n2yo.com/satellites/?c=52&srt=2&dir=1'
page = requests.get(URL)
soup = BeautifulSoup(page.content, 'html.parser')
table = soup.find("table", id="categoriestab")
rows = table.find_all('tr')
for row in rows:
cols = row.find_all('td')
cols = [ele.text.strip() for ele in cols]
data.append([ele for ele in cols if ele]) # Get rid of empty values
print(data)