假设我有一个数据框,由"年份"和"认知障碍"(1=是,0=否)组成。
然而,我认为使用broom或purrr可以使这些分析更简单。我的目标是拥有像这样的表格:
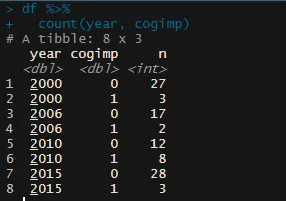
df %>%
filter(year == 2000) %>%
{prop.test(rev(table(.$cogimp)),p = 0.5, conf.level=0.95)}
而我可以通过以下方式检查:
prop.test(x = 3, n = 30, p = 0.5, conf.level=0.95)
然而,我认为使用broom或purrr可以使这些分析更简单。我的目标是拥有像这样的表格:
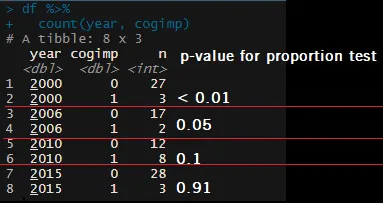
代码如下:
df <- structure(list(year = c(2000, 2000, 2015, 2015, 2000, 2015, 2000,
2000, 2000, 2000, 2015, 2006, 2015, 2015, 2010, 2006, 2006, 2010,
2000, 2006, 2015, 2006, 2015, 2015, 2000, 2015, 2000, 2015, 2015,
2010, 2015, 2015, 2015, 2000, 2006, 2006, 2006, 2015, 2015, 2006,
2015, 2010, 2000, 2000, 2010, 2006, 2010, 2010, 2015, 2000, 2015,
2006, 2000, 2006, 2015, 2006, 2000, 2010, 2010, 2010, 2015, 2006,
2015, 2000, 2015, 2010, 2010, 2010, 2010, 2000, 2000, 2000, 2006,
2015, 2015, 2000, 2000, 2000, 2015, 2006, 2006, 2010, 2006, 2000,
2010, 2000, 2015, 2015, 2015, 2015, 2010, 2000, 2000, 2010, 2006,
2010, 2010, 2000, 2000, 2000), cogimp = c(0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1,
1, 1, 0, 0, 0, 0, 0, 0, 0)), row.names = c(NA, -100L), class = c("tbl_df",
"tbl", "data.frame"))
df %>%
count(year, cogimp)
df %>%
filter(year == 2006) %>%
{prop.test(rev(table(.$cogimp)),p = 0.5, conf.level=0.95)}
prop.test(x = 3, n = 30, p = 0.5, conf.level=0.95)
prop.test(x = 2, n = 19, p = 0.5, conf.level=0.95)