我使用sttp lib与akka backend从服务器加载文件。以下两种方法之一都会导致加载1Gb文件时显著的内存占用:
import com.softwaremill.sttp._
val file: File = new File(...)
sttp.response(asStream[Source[ByteString, Any]])
.mapResponse { src =>
src.runWith(FileIO.toPath(file.toPath, options, 0))
}
sttp.response(asFile(file, false))
1GB文件的顺序加载的VisualVM图表。
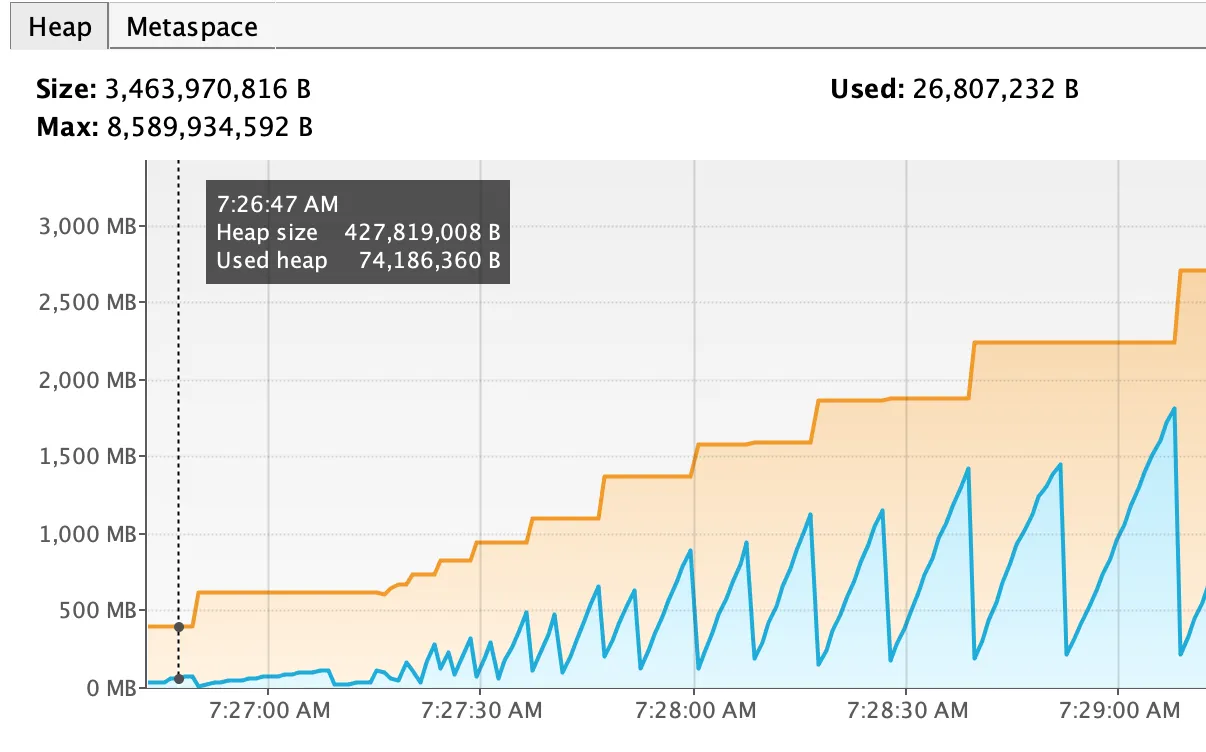
是否有可能将数据分块写入,并在写入后立即从内存中删除块?
val rd = new BufferedReader(new InputStreamReader(response.getEntity.getContent), 8192)- morsik