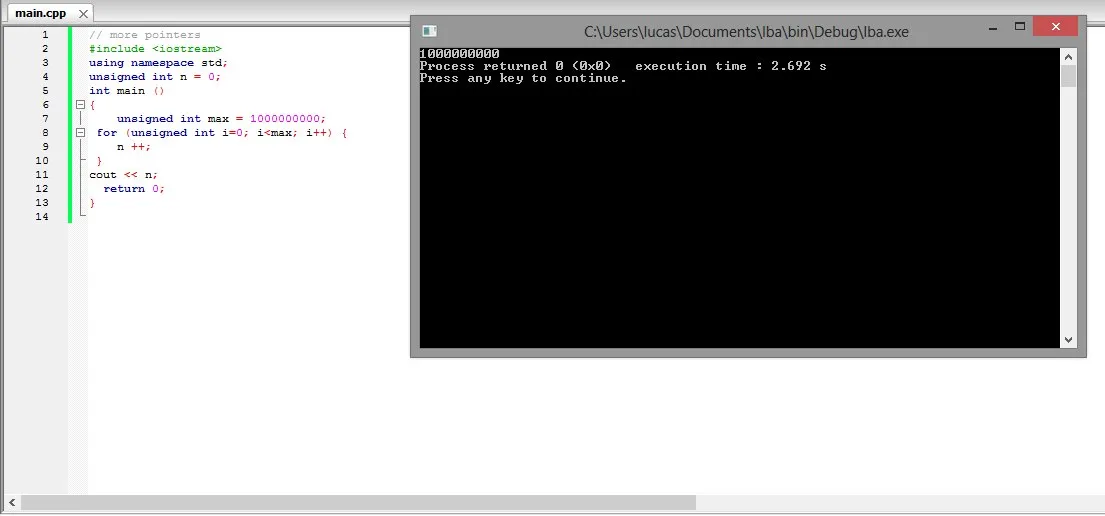
这是我的MacBook Air在c++中的结果,执行时间为2.692秒
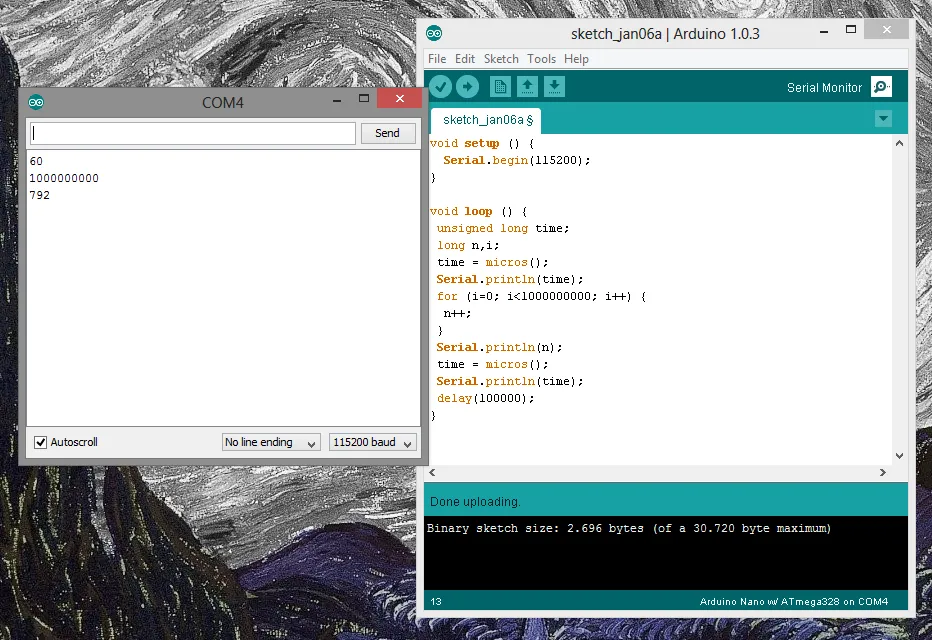
这是我的Arduino代码。它在'for'之前和之后获取微秒级别的时间。
差值为732微秒,即0.000732秒
让我们看看在调试模式下,MSVC如何编译您的代码,因为您似乎正在编译它...
unsigned int max = 1000000000L;
011643BE mov dword ptr [max],3B9ACA00h
for (unsigned int i=0; i<max; i++)
011643C5 mov dword ptr [ebp-14h],0
011643CC jmp main+37h (011643D7h)
011643CE mov eax,dword ptr [ebp-14h]
011643D1 add eax,1
011643D4 mov dword ptr [ebp-14h],eax
011643D7 mov eax,dword ptr [ebp-14h]
011643DA cmp eax,dword ptr [max]
for (unsigned int i=0; i<max; i++)
011643DD jae main+4Eh (011643EEh)
{
n++;
011643DF mov eax,dword ptr ds:[0116F218h]
011643E4 add eax,1
011643E7 mov dword ptr ds:[0116F218h],eax
}
011643EC jmp main+2Eh (011643CEh)
好的,现在让我们在发布模式下看一下...
unsigned int max = 1000000000L;
for (unsigned int i=0; i<max; i++)
00FC1270 mov eax,dword ptr ds:[00FC4430h]
{
n++;
}
std::cout << n;
00FC1275 mov ecx,dword ptr ds:[0FC3030h]
00FC127B add eax,3B9ACA00h
00FC1280 push eax
00FC1281 mov dword ptr ds:[00FC4430h],eax
00FC1286 call dword ptr ds:[0FC3038h]
注意到区别了吗?发布模式已经完全优化掉了循环。
好的,现在让我们换个角度来看看Arduino是如何做到这一点的。准备好一些AVR汇编代码...
for(i=0; i<1000000000; i++)
{
n++;
}
Serial.println(n);
d8: c8 01 movw r24, r16
da: 40 e0 ldi r20, 0x00 ; 0
dc: 5a ec ldi r21, 0xCA ; 202
de: 6a e9 ldi r22, 0x9A ; 154
e0: 7b e3 ldi r23, 0x3B ; 59
e2: 2a e0 ldi r18, 0x0A ; 10
e4: 30 e0 ldi r19, 0x00 ; 0
e6: 0e 94 c4 04 call 0x988 ; 0x988 <_ZN5Print7printlnEli>
哇!它还将循环优化了!编译器真是个聪明的小家伙,不是吗?!?!
……如果你认真想一想,执行那么长的循环只需要0.0007秒有点太快了吧?只有大约43个时钟周期的时间——勉强足够调用Serial.println()。
首先,你编写的代码非常简单。这样的代码编译的结果将根据编译器和编译器设置而变化。一个正确配置的优化编译器通常会将其编译成n的最终值的普通赋值,而不需要任何循环。或者甚至可以完全消除n。在这种情况下,你实际上测量的是“空虚的”:一个几乎什么也不做的程序的启动和结束时间。
其次,你使用的测量方法在两个代码版本之间似乎完全不同。在第一个案例中,你似乎在使用系统级别的东西,这意味着它可能包括各种启动和包装时间到最终总数中。在第二个案例中,你将测量嵌入到实际代码中,确保只测量了循环(而这循环很可能被编译器消除)。
换句话说,你正在使用不一致的方法来计时可能根本不存在的内容。你得到的结果与代码性能几乎没有关系,更有可能毫无意义。
time = micros()是如何工作的?难道不应该先存储第一个时间,然后从第二个时间中减去第一个时间吗?否则,你只是在读取一些随机数。在Arduino上运行需要多长时间?一千零一,一千零二... - Robert Harveyfor循环不会被优化掉吗? - Blastfurnace