我经常在创建和处理一些字节数组的方法中遇到
可能是字节数组或
除了物理内存短缺之外,什么可能导致创建大字节数组(60MB)时出现
OutOfMemoryException。代码如下:
- 创建一个内存流以获取一些数据(大约60MB)。
- 创建与内存流相同大小的字节数组(大约60MB)
- 用来自内存流的字节填充数组
- 关闭内存流
- 处理来自字节数组的数据
- 离开该方法
OutOfMemoryException。但我不认为这是系统内存问题。应用程序内存使用量约为500MB(私有工作集),测试机是64位,RAM为4GB。可能是字节数组或
MemoryStream 使用的内存没有在方法结束后释放吗?但是,看起来这个内存并没有为进程分配,因为私有工作集只有500MB左右。除了物理内存短缺之外,什么可能导致创建大字节数组(60MB)时出现
OutOfMemoryException?
[编辑以添加代码示例]
源代码来自PdfSharp lib
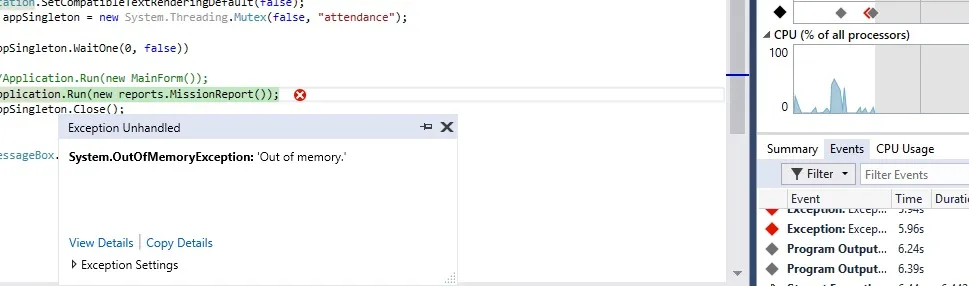
异常抛出在这一行:byte[] imageBits = new byte[streamLength]; 确实看起来像是 LOH 碎片问题。/// <summary>
/// Reads images that are returned from GDI+ without color palette.
/// </summary>
/// <param name="components">4 (32bpp RGB), 3 (24bpp RGB, 32bpp ARGB)</param>
/// <param name="bits">8</param>
/// <param name="hasAlpha">true (ARGB), false (RGB)</param>
private void ReadTrueColorMemoryBitmap(int components, int bits, bool hasAlpha)
{
int pdfVersion = Owner.Version;
MemoryStream memory = new MemoryStream();
image.gdiImage.Save(memory, ImageFormat.Bmp);
int streamLength = (int)memory.Length;
if (streamLength > 0)
{
byte[] imageBits = new byte[streamLength];
memory.Seek(0, SeekOrigin.Begin);
memory.Read(imageBits, 0, streamLength);
memory.Close();
int height = image.PixelHeight;
int width = image.PixelWidth;
if (ReadWord(imageBits, 0) != 0x4d42 || // "BM"
ReadDWord(imageBits, 2) != streamLength ||
ReadDWord(imageBits, 14) != 40 || // sizeof BITMAPINFOHEADER
ReadDWord(imageBits, 18) != width ||
ReadDWord(imageBits, 22) != height)
{
throw new NotImplementedException("ReadTrueColorMemoryBitmap: unsupported format");
}
if (ReadWord(imageBits, 26) != 1 ||
(!hasAlpha && ReadWord(imageBits, 28) != components * bits ||
hasAlpha && ReadWord(imageBits, 28) != (components + 1) * bits) ||
ReadDWord(imageBits, 30) != 0)
{
throw new NotImplementedException("ReadTrueColorMemoryBitmap: unsupported format #2");
}
int nFileOffset = ReadDWord(imageBits, 10);
int logicalComponents = components;
if (components == 4)
logicalComponents = 3;
byte[] imageData = new byte[components * width * height];
bool hasMask = false;
bool hasAlphaMask = false;
byte[] alphaMask = hasAlpha ? new byte[width * height] : null;
MonochromeMask mask = hasAlpha ?
new MonochromeMask(width, height) : null;
int nOffsetRead = 0;
if (logicalComponents == 3)
{
for (int y = 0; y < height; ++y)
{
int nOffsetWrite = 3 * (height - 1 - y) * width;
int nOffsetWriteAlpha = 0;
if (hasAlpha)
{
mask.StartLine(y);
nOffsetWriteAlpha = (height - 1 - y) * width;
}
for (int x = 0; x < width; ++x)
{
imageData[nOffsetWrite] = imageBits[nFileOffset + nOffsetRead + 2];
imageData[nOffsetWrite + 1] = imageBits[nFileOffset + nOffsetRead + 1];
imageData[nOffsetWrite + 2] = imageBits[nFileOffset + nOffsetRead];
if (hasAlpha)
{
mask.AddPel(imageBits[nFileOffset + nOffsetRead + 3]);
alphaMask[nOffsetWriteAlpha] = imageBits[nFileOffset + nOffsetRead + 3];
if (!hasMask || !hasAlphaMask)
{
if (imageBits[nFileOffset + nOffsetRead + 3] != 255)
{
hasMask = true;
if (imageBits[nFileOffset + nOffsetRead + 3] != 0)
hasAlphaMask = true;
}
}
++nOffsetWriteAlpha;
}
nOffsetRead += hasAlpha ? 4 : components;
nOffsetWrite += 3;
}
nOffsetRead = 4 * ((nOffsetRead + 3) / 4); // Align to 32 bit boundary
}
}
else if (components == 1)
{
// Grayscale
throw new NotImplementedException("Image format not supported (grayscales).");
}
FlateDecode fd = new FlateDecode();
if (hasMask)
{
// monochrome mask is either sufficient or
// provided for compatibility with older reader versions
byte[] maskDataCompressed = fd.Encode(mask.MaskData);
PdfDictionary pdfMask = new PdfDictionary(document);
pdfMask.Elements.SetName(Keys.Type, "/XObject");
pdfMask.Elements.SetName(Keys.Subtype, "/Image");
Owner.irefTable.Add(pdfMask);
pdfMask.Stream = new PdfStream(maskDataCompressed, pdfMask);
pdfMask.Elements[Keys.Length] = new PdfInteger(maskDataCompressed.Length);
pdfMask.Elements[Keys.Filter] = new PdfName("/FlateDecode");
pdfMask.Elements[Keys.Width] = new PdfInteger(width);
pdfMask.Elements[Keys.Height] = new PdfInteger(height);
pdfMask.Elements[Keys.BitsPerComponent] = new PdfInteger(1);
pdfMask.Elements[Keys.ImageMask] = new PdfBoolean(true);
Elements[Keys.Mask] = pdfMask.Reference;
}
if (hasMask && hasAlphaMask && pdfVersion >= 14)
{
// The image provides an alpha mask (requires Arcrobat 5.0 or higher)
byte[] alphaMaskCompressed = fd.Encode(alphaMask);
PdfDictionary smask = new PdfDictionary(document);
smask.Elements.SetName(Keys.Type, "/XObject");
smask.Elements.SetName(Keys.Subtype, "/Image");
Owner.irefTable.Add(smask);
smask.Stream = new PdfStream(alphaMaskCompressed, smask);
smask.Elements[Keys.Length] = new PdfInteger(alphaMaskCompressed.Length);
smask.Elements[Keys.Filter] = new PdfName("/FlateDecode");
smask.Elements[Keys.Width] = new PdfInteger(width);
smask.Elements[Keys.Height] = new PdfInteger(height);
smask.Elements[Keys.BitsPerComponent] = new PdfInteger(8);
smask.Elements[Keys.ColorSpace] = new PdfName("/DeviceGray");
Elements[Keys.SMask] = smask.Reference;
}
byte[] imageDataCompressed = fd.Encode(imageData);
Stream = new PdfStream(imageDataCompressed, this);
Elements[Keys.Length] = new PdfInteger(imageDataCompressed.Length);
Elements[Keys.Filter] = new PdfName("/FlateDecode");
Elements[Keys.Width] = new PdfInteger(width);
Elements[Keys.Height] = new PdfInteger(height);
Elements[Keys.BitsPerComponent] = new PdfInteger(8);
// TODO: CMYK
Elements[Keys.ColorSpace] = new PdfName("/DeviceRGB");
if (image.Interpolate)
Elements[Keys.Interpolate] = PdfBoolean.True;
}
}

ReadTrueColorMemoryBitmap()之后或结束时进行。 - H HSystem.IO.UnmanagedMemoryStream。问题是你必须事先知道所需的空间。或者至少有一个上限。文档明确表示此流不会在堆上分配内存。另一个问题是您的程序需要安全设置以允许执行此操作。 - JotaBe