我想要在pyspark中读取一个AWS Glue表格,但是遇到了NullPointerException错误:
spark.sql("show tables").show()
+----------------+-----------------+-----------+
| database| tableName|isTemporary|
+----------------+-----------------+-----------+
|test_datalake_db|events2_2017_test| false|
|test_datalake_db| events2_old| false|
+----------------+-----------------+-----------+
接下来,我尝试从表中选择一些内容:
df = spark.sql("select * from events2_2017_test")
然而,事情变得有些混乱:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib/spark/python/pyspark/sql/session.py", line 603, in sql
return DataFrame(self._jsparkSession.sql(sqlQuery), self._wrapped)
File "/usr/lib/spark/python/lib/py4j-0.10.4-src.zip/py4j/java_gateway.py", line 1133, in __call__
File "/usr/lib/spark/python/pyspark/sql/utils.py", line 63, in deco
return f(*a, **kw)
File "/usr/lib/spark/python/lib/py4j-0.10.4-src.zip/py4j/protocol.py", line 319, in get_return_value
py4j.protocol.Py4JJavaError: An error occurred while calling o51.sql.
: java.lang.NullPointerException: Name is null
at java.lang.Enum.valueOf(Enum.java:236)
同样会出现以下错误:
myDf = spark.table("test_datalake_db.events2_2017_test")
这是表的架构:
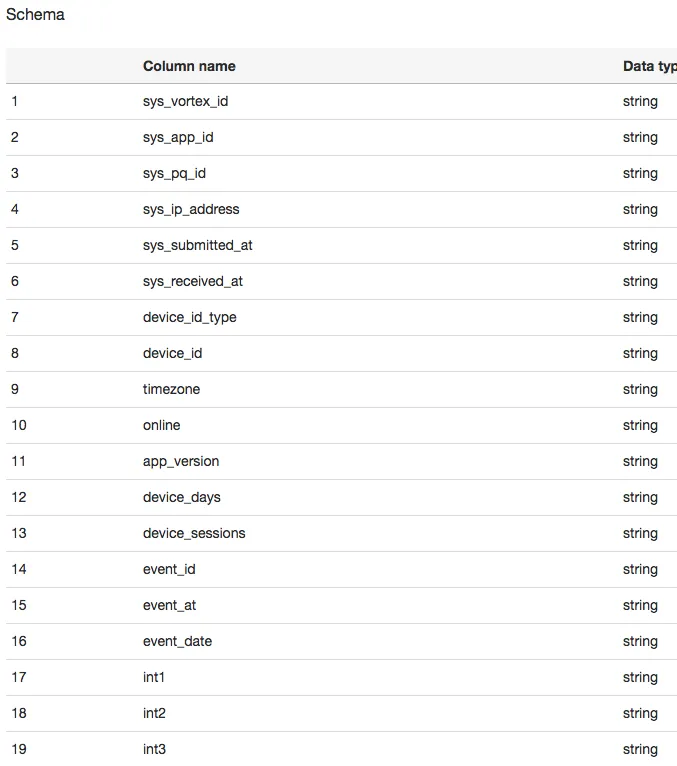
events2_2017_test中的列名是什么? - Andreas Ryge