我怀疑真正的问题在于您的迭代内核运行时间非常短(大约100微秒或更短),意味着每次迭代的工作量非常小。最好的解决方案可能是尝试增加每次迭代的工作量(重构您的代码/算法,处理更大的问题等)。
然而,以下是一些可能性:
1. 使用映射/固定内存。在没有比我们可能无法查看的书籍参考页面的情况下,我认为您在问题的第2项中的声明是不可支持的。
2. 使用动态并行性。将内核启动过程移动到发出子内核的CUDA父内核中。由子内核设置的任何布尔值都将立即在父内核中发现,无需进行cudaMemcpy操作或映射/固定内存。
3. 使用流水线算法,并将假设内核启动与每个管道阶段的设备->主机复制重叠,以进行布尔值。
我认为前两项很明显,因此我将为第三项提供一个实例。基本思想是我们将在两个流之间来回反弹,交替地将内核启动到一个流中,然后是另一个流。我们将有第三个流,以便我们可以将设备->主机复制操作与下一次启动的执行重叠。由于D->H复制与内核执行的重叠,复制操作实际上没有任何“成本”,它被内核执行工作隐藏了。
这里有一个完整的示例,以及nvvp时间轴:
$ cat t267.cu
#include <stdio.h>
const int stop_count = 5;
const long long tdelay = 1000000LL;
__global__ void test_kernel(int *icounter, bool *istop, int *ocounter, bool *ostop){
if (*istop) return;
long long start = clock64();
while (clock64() < tdelay+start);
int my_count = *icounter;
my_count++;
if (my_count >= stop_count) *ostop = true;
*ocounter = my_count;
}
int main(){
volatile bool *v_stop;
volatile int *v_counter;
bool *h_stop, *d_stop1, *d_stop2, *d_s1, *d_s2, *d_ss;
int *h_counter, *d_counter1, *d_counter2, *d_c1, *d_c2, *d_cs;
cudaStream_t s1, s2, s3, *sp1, *sp2, *sps;
cudaEvent_t e1, e2, *ep1, *ep2, *eps;
cudaStreamCreate(&s1);
cudaStreamCreate(&s2);
cudaStreamCreate(&s3);
cudaEventCreate(&e1);
cudaEventCreate(&e2);
cudaMalloc(&d_counter1, sizeof(int));
cudaMalloc(&d_stop1, sizeof(bool));
cudaMalloc(&d_counter2, sizeof(int));
cudaMalloc(&d_stop2, sizeof(bool));
cudaHostAlloc(&h_stop, sizeof(bool), cudaHostAllocDefault);
cudaHostAlloc(&h_counter, sizeof(int), cudaHostAllocDefault);
v_stop = h_stop;
v_counter = h_counter;
int n_counter = 1;
h_stop[0] = false;
h_counter[0] = 0;
cudaMemcpy(d_stop1, h_stop, sizeof(bool), cudaMemcpyHostToDevice);
cudaMemcpy(d_stop2, h_stop, sizeof(bool), cudaMemcpyHostToDevice);
cudaMemcpy(d_counter1, h_counter, sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_counter2, h_counter, sizeof(int), cudaMemcpyHostToDevice);
sp1 = &s1;
sp2 = &s2;
ep1 = &e1;
ep2 = &e2;
d_c1 = d_counter1;
d_c2 = d_counter2;
d_s1 = d_stop1;
d_s2 = d_stop2;
test_kernel<<<1,1, 0, *sp1>>>(d_c1, d_s1, d_c2, d_s2);
cudaEventRecord(*ep1, *sp1);
cudaStreamWaitEvent(s3, *ep1, 0);
cudaMemcpyAsync(h_stop, d_s2, sizeof(bool), cudaMemcpyDeviceToHost, s3);
cudaMemcpyAsync(h_counter, d_c2, sizeof(int), cudaMemcpyDeviceToHost, s3);
while (v_stop[0] == false){
cudaStreamWaitEvent(*sp2, *ep1, 0);
sps = sp1;
sp1 = sp2;
sp2 = sps;
eps = ep1;
ep1 = ep2;
ep2 = eps;
d_cs = d_c1;
d_c1 = d_c2;
d_c2 = d_cs;
d_ss = d_s1;
d_s1 = d_s2;
d_s2 = d_ss;
test_kernel<<<1,1, 0, *sp1>>>(d_c1, d_s1, d_c2, d_s2);
cudaEventRecord(*ep1, *sp1);
while (n_counter > v_counter[0]);
n_counter++;
if(v_stop[0] == false){
cudaStreamWaitEvent(s3, *ep1, 0);
cudaMemcpyAsync(h_stop, d_s2, sizeof(bool), cudaMemcpyDeviceToHost, s3);
cudaMemcpyAsync(h_counter, d_c2, sizeof(int), cudaMemcpyDeviceToHost, s3);
}
}
cudaDeviceSynchronize();
printf("terminated at counter = %d\n", v_counter[0]);
}
$ nvcc -arch=sm_52 -o t267 t267.cu
$ ./t267
terminated at counter = 5
$
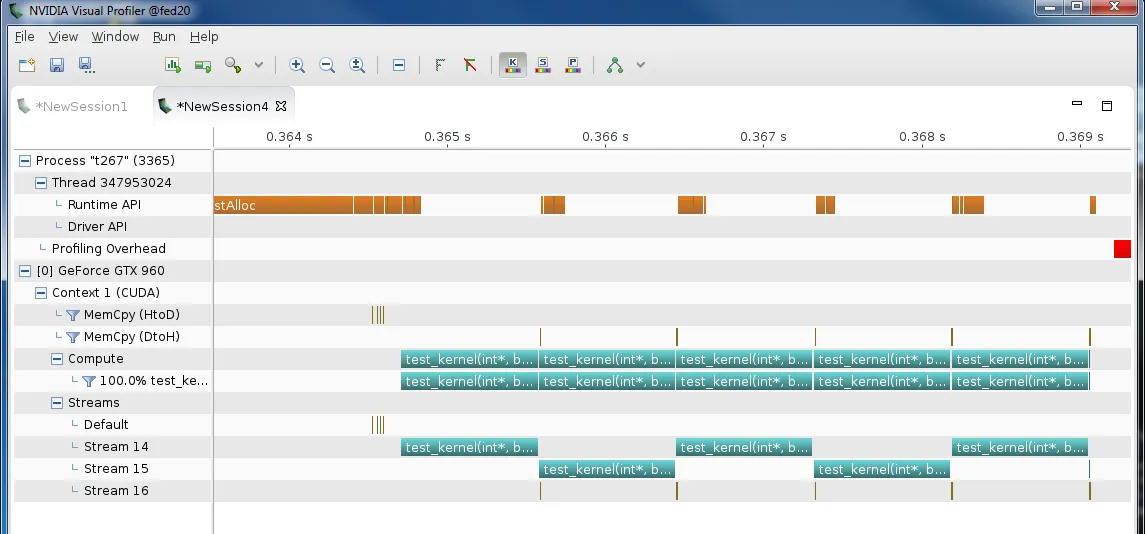
在上图中,我们可以看到有5个内核启动(实际上是6个),它们在两个流之间来回跳动。(第6个内核启动应该来自代码组织和流水线,但在上面的stream15末尾只有一个非常短的行。这个内核启动,但立即发现
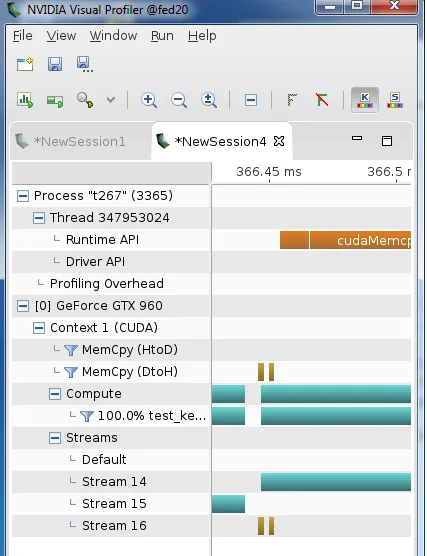
stop为真,所以退出。)设备 -> 主机复制在第三个流中。如果我们仔细观察从一个内核迭代到下一个内核迭代的交接处:
我们可以看到,即使是这些非常短的D->H memcpy操作也基本上与下一个内核执行重叠。请注意,以上所有操作都在Linux上完成。如果您在Windows WDDM上尝试此操作,可能很难实现类似的效果,因为WDDM命令批处理存在。但是,Windows TCC应该可以近似复制Linux的行为。