我已经有一个可运行的解决方案,但我真的想知道为什么这个方法不起作用:
ratings = Model.select(:rating).uniq
ratings.each { |r| puts r.rating }
我已经有一个可运行的解决方案,但我真的想知道为什么这个方法不起作用:
ratings = Model.select(:rating).uniq
ratings.each { |r| puts r.rating }
Model.select(:rating)
Model 对象的集合,而不是普通的评分。从 uniq 的角度来看,它们完全不同。你可以使用以下方法:这会生成一个Model对象的集合,而不是简单的评分。从 uniq 的角度来看,它们是完全不同的。你可以使用以下代码:
Model.select(:rating).map(&:rating).uniq
或者选择这个(最有效):
Model.uniq.pluck(:rating)
Model.distinct.pluck(:rating)
显然,在Rails 5.0.0.1中,它仅适用于像上面那样的“顶级”查询。在集合代理(例如“has_many”关系)上不起作用。
Address.distinct.pluck(:city) # => ['Moscow']
user.addresses.distinct.pluck(:city) # => ['Moscow', 'Moscow', 'Moscow']
user.addresses.pluck(:city).uniq # => ['Moscow']
Model.uniq.pluck(:rating) 是最有效的方法 - 它会生成使用 SELECT DISTINCT 的 SQL,而不是对数组应用.uniq。 - MikeyModel.related_records.group(:some_column).pluck(:some_column)。 - Krzysztof KarskiModel.distinct.pluck(:rating) 对我也有效。 - EliadL如果你打算使用Model.select,那么最好直接使用DISTINCT,因为它只会返回唯一值。这样做更好,因为它意味着它返回的行数更少,应该比返回多行然后告诉Rails挑选唯一值更快。
Model.select('DISTINCT rating')
当然,前提是您的数据库能理解DISTINCT关键字,大多数数据库都可以。
Model.select("DISTINCT rating").map(&:rating)获取一个仅包含评分的数组。 - Kris这也有效。
Model.pluck("DISTINCT rating")
pluck是一个纯粹的Rails 3.2以上版本方法,不依赖于Ruby 1.9.x。详情请参见http://apidock.com/rails/v3.2.1/ActiveRecord/Calculations/pluck。 - Daniel RikowskiModel.pluck(Arel.sql("DISTINCT rating"))。该方法可实现相同的功能。 - Rocket Appliances如果您还想选择额外的字段:
Model.select('DISTINCT ON (models.ratings) models.ratings, models.id').map { |m| [m.id, m.ratings] }
Model.uniq.pluck(:rating)
# SELECT DISTINCT "models"."rating" FROM "models"
这样做的好处是不使用SQL字符串和实例化模型。
Model.select(:rating).uniq
这段代码起到了“DISTINCT”作用(不是Array#uniq),自 rails 3.2 起可用。
在 Rails 6 及以上版本中,应为:
Model.select(:rating).distinct
DISTINCT子句,因此它是一个SELECT models.rating FROM models,然后使用Array#uniq。 - Rocket AppliancesModel.select(:rating).distinct
.pluck(:rating)将使其完全符合 OP 的要求。 - Sheharyar使用SQL收集唯一列的另一种方法:
Model.group(:rating).pluck(:rating)
当前查询:
Model.select(:rating)
Model.select(:rating).uniq
uniq 用于对象数组,每个对象都有唯一的 ID。uniq 的工作正常,因为数组中的每个对象都是唯一的。
选择不同的评级方法有很多种:
Model.select('distinct rating').map(&:rating)
Model.select('distinct rating').collect(&:rating)
或者
Model.select(:rating).map(&:rating).uniq
Model.select(:name).collect(&:rating).uniq
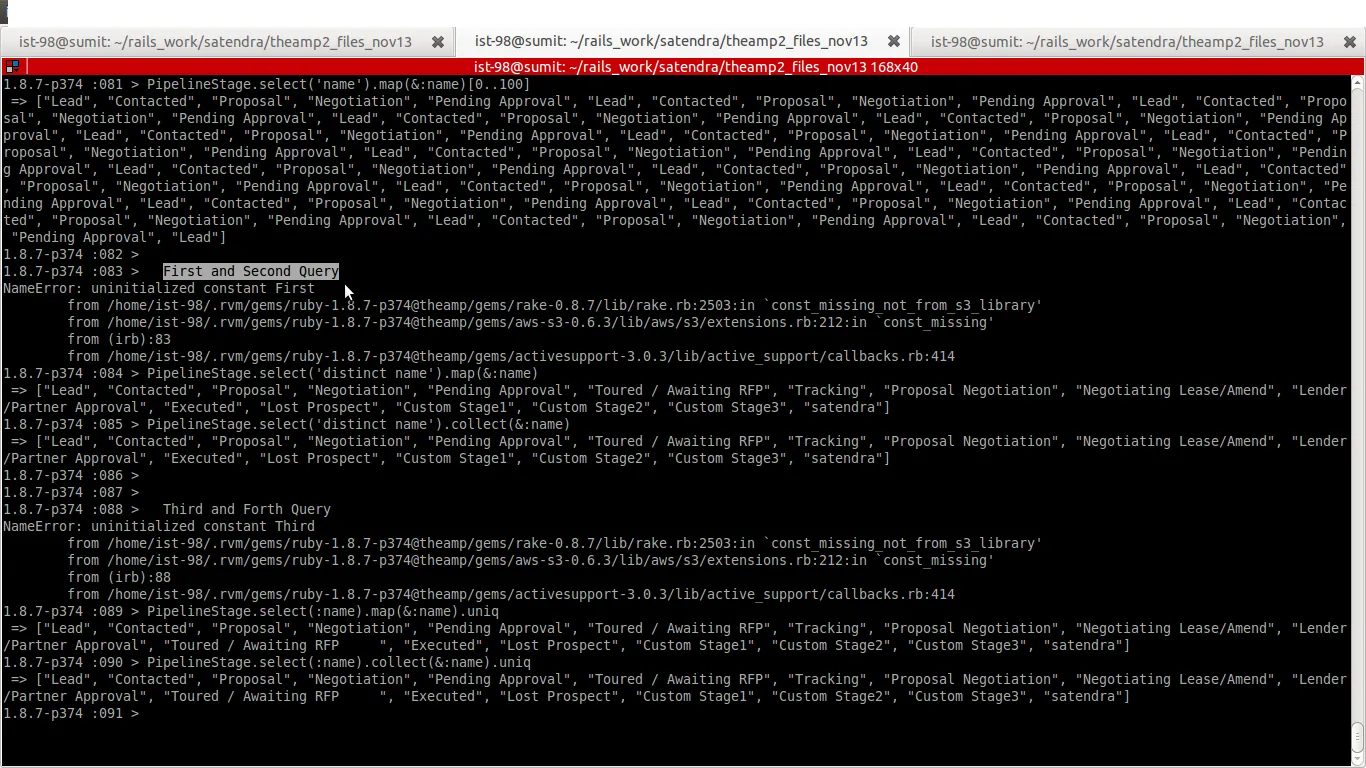
还有一件事,第一和第二个查询:通过SQL查询查找不同的数据。
这些查询将认为“london”和“london ”相同,这意味着它会忽略空格,因此在查询结果中只选择“london”一次。
第三和第四个查询:
通过SQL查询查找数据,并应用ruby uniq方法来查找不同的数据。这些查询将认为“london”和“london ”不同,因此在查询结果中选择“london”和“london ”。
请参考附加的图片以获得更好的理解,并查看“已巡游/等待RFP”。
map和collect是同一个方法的别名,不需要为两者都提供示例。 - Adam Lassek有些答案没有考虑到OP想要一个值数组
其他答案在模型具有数千条记录时效果不佳
仍然,我认为一个好的答案是:
Model.uniq.select(:ratings).map(&:ratings)
=> "SELECT DISTINCT ratings FROM `models` "
首先,您需要生成一个模型数组(由于选择而减小大小),然后提取这些选定模型具有的唯一属性(评级)。