背景
我有一个代码生成器,可以在Rust中生成长表达式,但编译器似乎不能很好地处理它们。在这些示例中,我使用常量/加法来简化,但实际上,我希望支持涉及变量和其他编程结构的更复杂的表达式。
例子
fn main() {
let _x = 1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1
+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1
+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1
// ...
// 500 identical lines
// ...
+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1
+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1
;
}
当我尝试编译它时,它会崩溃并显示“分段错误(core dumped)”的代码。(如果中间行数少一些就可以工作,因此我认为这只是由表达式长度引起的崩溃。)
我尝试过的方法
添加额外括号
我尝试在各个地方添加括号。在每行的开头和结尾加上括号可以防止崩溃但却需要一个小时才能编译(也更改了语义学,因为操作顺序不同):
fn main() {
let _x = 1+(1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1)
+(1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1)
+(1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1)
// ...
// 8000 identical lines
// ...
+(1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1)
+(1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1)
;
}
fasteval
fasteval 看起来可以更快地处理表达式,但仅限于基本变量操作和函数调用,因此无法处理表达式和更复杂的 Rust 代码的混合。
变量
将每个表达式分解为许多生成的变量(每个二元运算符一个变量)也可以防止崩溃,但在变量数量上具有二次编译时间(例如,添加8000个数字需要9秒,添加16000个数字需要37秒)。
将表达式分解为多个函数
这看起来应该可行,但在代码生成方面需要更多的工作。
更改编译器
查看 Rust 编译器源代码,似乎缓慢可能来自于树操作时抽象语法节点的大量克隆。感觉底层数据很多时候是不可变的,因此可能可以重用对现有不可变数据的引用,而不是复制整个树。然而,这可能需要相当大的努力才能使其正常工作。
问题
有没有其他方法可以避免Rust中编译大表达式的缓慢编译时间?(这是我的第一个Rust程序,所以我可能忽略了一些明显的东西,比如编译器标志或者更符合惯用方式的表达式写法)更新:
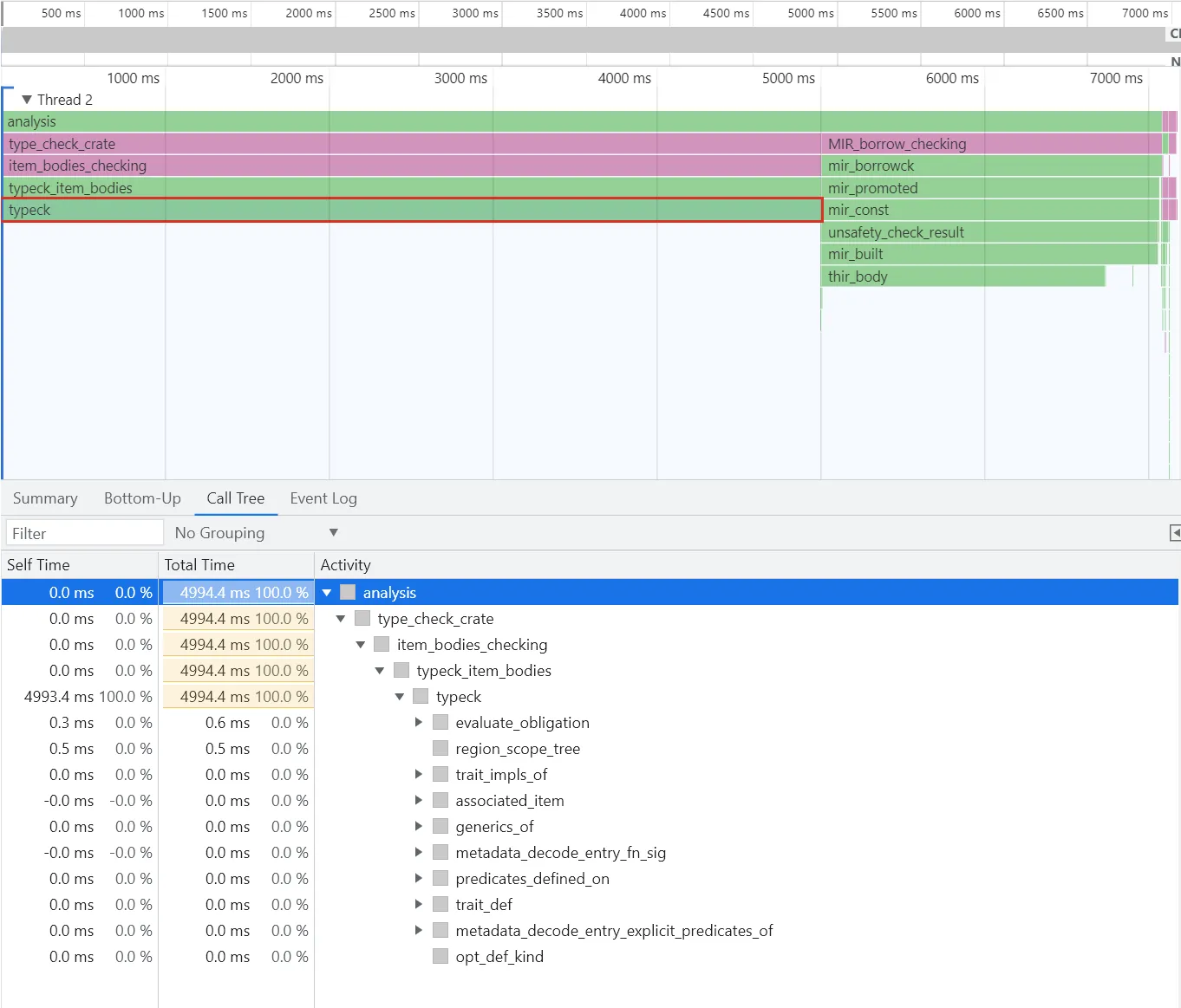
编译器的示例配置输出。
+-------------------------------------------------+-----------+-----------------+----------+------------+
| Item | Self time | % of total time | Time | Item count |
+-------------------------------------------------+-----------+-----------------+----------+------------+
| typeck | 4.99s | 69.503 | 4.99s | 1 |
+-------------------------------------------------+-----------+-----------------+----------+------------+
| thir_body | 1.73s | 24.112 | 1.73s | 1 |
+-------------------------------------------------+-----------+-----------------+----------+------------+
| mir_built | 328.48ms | 4.572 | 2.06s | 1 |
+-------------------------------------------------+-----------+-----------------+----------+------------+
| run_linker | 50.88ms | 0.708 | 50.88ms | 1 |
+-------------------------------------------------+-----------+-----------------+----------+------------+
...
改用括号和i32
正如Chayim Friedman在下面的回答中建议的那样,可以通过使用1i32来避免类型检查时间。现在,该文件的profile大部分时间都花费在thir_body中(3k行文件的profile):
+-------------------------------------------------+-----------+-----------------+----------+------------+
| Item | Self time | % of total time | Time | Item count |
+-------------------------------------------------+-----------+-----------------+----------+------------+
| thir_body | 6.49s | 73.044 | 6.49s | 1 |
+-------------------------------------------------+-----------+-----------------+----------+------------+
| mir_built | 1.02s | 11.506 | 7.51s | 1 |
+-------------------------------------------------+-----------+-----------------+----------+------------+
| mir_borrowck | 402.33ms | 4.529 | 7.93s | 1 |
+-------------------------------------------------+-----------+-----------------+----------+------------+
| mir_drops_elaborated_and_const_checked | 394.76ms | 4.444 | 394.80ms | 1 |
+-------------------------------------------------+-----------+-----------------+----------+------------+
| typeck | 306.75ms | 3.453 | 312.72ms | 1 |
+-------------------------------------------------+-----------+-----------------+----------+------------+
| optimized_mir | 118.45ms | 1.333 | 513.32ms | 5 |
+-------------------------------------------------+-----------+-----------------+----------+------------+
| run_linker | 52.22ms | 0.588 | 52.22ms | 1 |
+-------------------------------------------------+-----------+-----------------+----------+------------+
let x = 1 + 1 + 1 + 1 ...;可以替换为let mut x = 0; x += 1; x += 1; x += 1; ...。 - kaya3