我希望将数据从BigQuery迁移到CloudSQL以节省成本。
我的问题是,与BigQuery相比,使用PostgreSQL的CloudSQL非常非常慢。
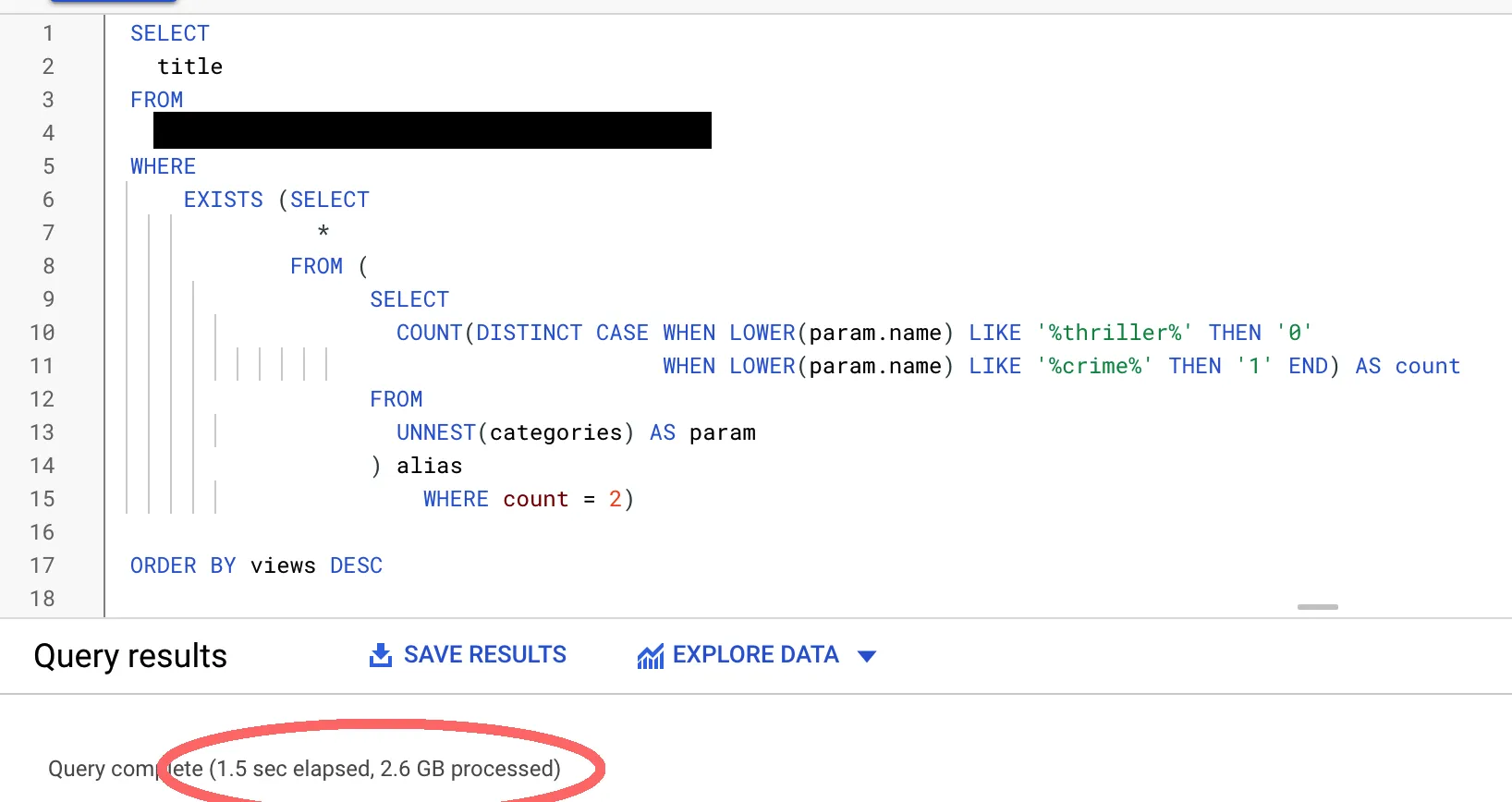
在BigQuery中需要1.5秒的查询,在CloudSQL中使用PostgreSQL则需要将近4.5分钟!
我有一个具有以下配置的CloudSQL PostgreSQL服务器:

我的数据库有一个主表,有1600万行(在内存中大约14GB)。
一个例子查询:
EXPLAIN ANALYZE
SELECT
"title"
FROM
public.videos
WHERE
EXISTS (SELECT
*
FROM (
SELECT
COUNT(DISTINCT CASE WHEN LOWER(param) LIKE '%thriller%' THEN '0'
WHEN LOWER(param) LIKE '%crime%' THEN '1' END) AS count
FROM
UNNEST(categories) AS param
) alias
WHERE count = 2)
ORDER BY views DESC
LIMIT 12 OFFSET 0
这个表是一个名为videos的表,其中有一个categories列,类型为text[]。
这里的搜索条件是查找具有'%thriller%'和'%crime%'的类别恰好出现两次的记录。
此查询的EXPLAIN ANALYZE输出结果(CSV):link。 此查询的EXPLAIN(BUFFERS)输出结果(CSV):link。
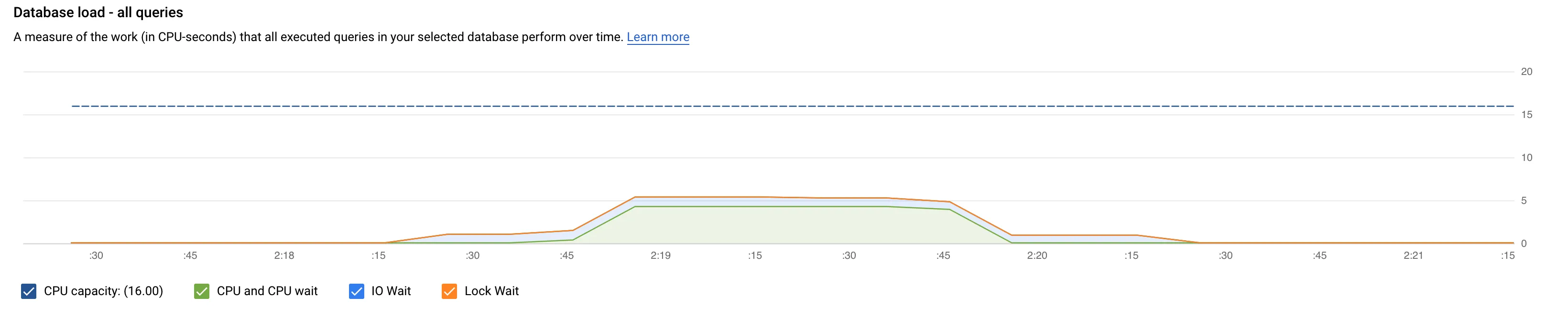
查询洞察图:
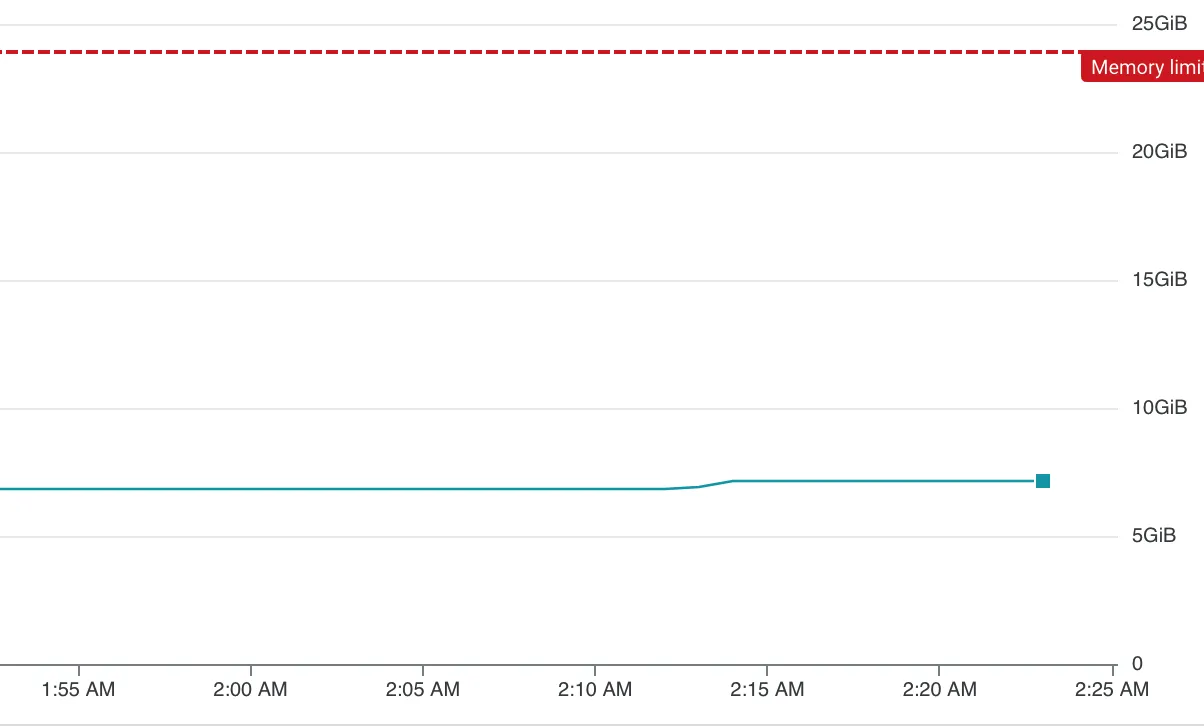
内存概要:
对于相同的表格大小,BigQuery查询的参考:
服务器配置:链接。
表格描述:链接。
我的目标是让Cloud SQL具有与Big Query相同的查询速度。