我需要抽取10个0到1之间均匀分布的随机数。因此,我认为以下Python代码可以实现这一目标:
然而,将结果放入直方图中,结果如下所示:
positions = []
for dummy_i in range(1000000):
positions.append(round(random.random(),1))
然而,将结果放入直方图中,结果如下所示:
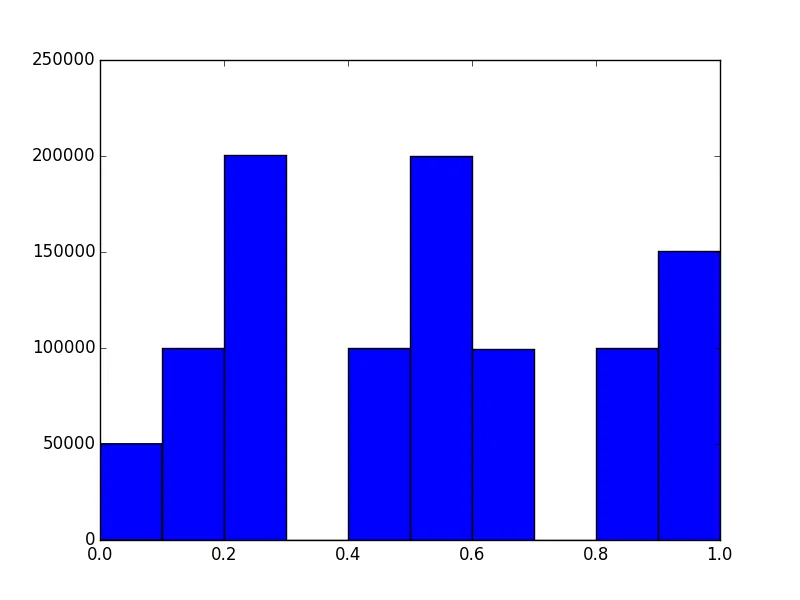
collections.Counter:尝试运行collections.Counter(round(random.random(), 1) for _ in range(10**6)),你会发现对于0.1到0.9的计数大致相等。 - Mark Dickinson