我在从字符串中删除非UTF-8字符方面遇到了问题,这些字符无法正确显示。这些字符的表示形式如0x97 0x61 0x6C 0x6F(十六进制表示)。
最好的方法是什么?使用正则表达式还是其他什么?
我在从字符串中删除非UTF-8字符方面遇到了问题,这些字符无法正确显示。这些字符的表示形式如0x97 0x61 0x6C 0x6F(十六进制表示)。
最好的方法是什么?使用正则表达式还是其他什么?
欢迎来到2019年和正则表达式中的/u修饰符,它将为您处理UTF-8多字节字符
如果您只使用mb_convert_encoding($value, 'UTF-8', 'UTF-8'),您仍然会在字符串中遇到非可打印字符
此方法将:
mb_convert_encoding删除所有无效的UTF-8多字节字符preg_replace删除所有不可打印的字符,如\r、\x00(NULL-byte)和其他控制字符function utf8_filter(string $value): string{
return preg_replace('/[^[:print:]\n]/u', '', mb_convert_encoding($value, 'UTF-8', 'UTF-8'));
}
[:print:] 匹配所有可打印字符和换行符 \n 并剥离其他所有内容。
您可以在下面看到ASCII表。可打印字符的范围为32到127,但换行符\n是控制字符的一部分,控制字符的范围从0到31,因此我们必须将换行符添加到正则表达式/[^[:print:]\n]/u中。
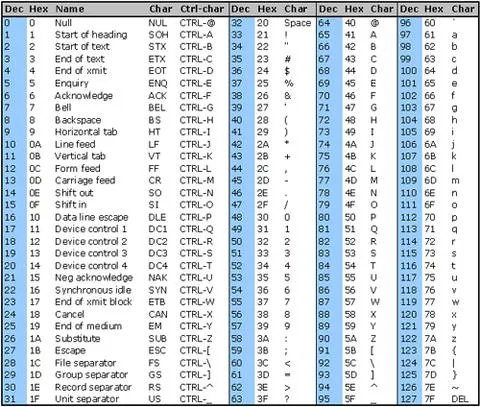
您可以尝试发送字符串通过使用可打印范围以外的字符进行正则表达式匹配,例如\x7F(DEL),\x1B(Esc)等,并查看它们如何被剥离。
function utf8_filter(string $value): string{
return preg_replace('/[^[:print:]\n]/u', '', mb_convert_encoding($value, 'UTF-8', 'UTF-8'));
}
$arr = [
'Danish chars' => 'Hello from Denmark with æøå',
'Non-printable chars' => "\x7FHello with invalid chars\r \x00"
];
foreach($arr as $k => $v){
echo "$k:\n---------\n";
$len = strlen($v);
echo "$v\n(".$len.")\n";
$strip = utf8_decode(utf8_filter(utf8_encode($v)));
$strip_len = strlen($strip);
echo $strip."\n(".$strip_len.")\n\n";
echo "Chars removed: ".($len - $strip_len)."\n\n\n";
}
php-mbstring不再默认打包在php中。 - NVRM\r和\n,为什么不使用\R呢? - mickmackusautf8_encode 没有意义。如果您的字符串采用 ISO 8859-1 编码,则该函数将其转换为 UTF-8。如果它是其他任何编码,包括 UTF-8,它都将把它转换为乱码字符串,这将是有效的 UTF-8。因此,最终您将在乱码字符串上运行“删除非可打印字符”的正则表达式,并从另一端获得一堆无意义的结果。 - IMSoP$string = preg_replace('~&([a-z]{1,2})(acute|cedil|circ|grave|lig|orn|ring|slash|th|tilde|uml);~i', '$1', htmlentities($string, ENT_COMPAT, 'UTF-8'));
substr()可能会破坏您的多字节字符!
在我的情况下,我使用substr($string,0,255)来确保用户提供的值可以适合数据库。有时它会将多字节字符拆分成两半,并导致数据库出现“不正确的字符串值”错误。
您可以使用mb_substr($string,0,255),对于MySQL 5而言这可能没问题,但是MySQL 4会计算字节而不是字符,因此根据多字节字符的数量仍然会太长。
为了避免这些问题,我实施了以下步骤:
mb_substring以防仍然太长。最近对Drupal的Feeds JSON解析模块进行了补丁升级:
//remove everything except valid letters (from any language)
$raw = preg_replace('/(?:\\\\u[\pL\p{Zs}])+/', '', $raw);
iconv 要比老式的基于正则表达式的 preg_replace 好得多,后者现在已经过时了。 - m3ndaereg_replace(),抱歉。 - m3nda\u后面的字符类中匹配unicode空格字符?我很少使用表情符号,所以也许你知道比我更多。请设置一个工作演示来证明你的preg调用如何以及做了什么。 - mickmackusa规则是第一个UTF-8八位字节的高位被设置为标记,然后使用1到4个比特表示有多少个附加八位字节;然后每个附加的八位字节必须将高两位设置为10。
伪Python代码如下:
newstring = ''
cont = 0
for each ch in string:
if cont:
if (ch >> 6) != 2: # high 2 bits are 10
# do whatever, e.g. skip it, or skip whole point, or?
else:
# acceptable continuation of multi-octlet char
newstring += ch
cont -= 1
else:
if (ch >> 7): # high bit set?
c = (ch << 1) # strip the high bit marker
while (c & 1): # while the high bit indicates another octlet
c <<= 1
cont += 1
if cont > 4:
# more than 4 octels not allowed; cope with error
if !cont:
# illegal, do something sensible
newstring += ch # or whatever
if cont:
# last utf-8 was not terminated, cope
这个逻辑同样适用于php。然而,一旦出现格式错误的字符,需要进行哪种类型的剥离处理并不清楚。
c = (ch << 1)会使得第一次(c & 1)为零,从而跳过循环。测试应该是(c & 128)。 - Markus Jarderot
$string = mb_convert_encoding($string, 'UTF-8', 'UTF-8');
$string = iconv("UTF-8", "UTF-8//IGNORE", $string);
我尝试了许多关于这个主题的解决方案,但是在我的特定情况下,它们都没有起作用。但是我在这个链接中找到了一个好的解决方案:
https://www.ryadel.com/en/php-skip-invalid-characters-utf-8-xml-file-string/基本上,这个函数解决了我的问题:
function sanitizeXML($string)
{
if (!empty($string))
{
// remove EOT+NOREP+EOX|EOT+<char> sequence (FatturaPA)
$string = preg_replace('/(\x{0004}(?:\x{201A}|\x{FFFD})(?:\x{0003}|\x{0004}).)/u', '', $string);
$regex = '/(
[\xC0-\xC1] # Invalid UTF-8 Bytes
| [\xF5-\xFF] # Invalid UTF-8 Bytes
| \xE0[\x80-\x9F] # Overlong encoding of prior code point
| \xF0[\x80-\x8F] # Overlong encoding of prior code point
| [\xC2-\xDF](?![\x80-\xBF]) # Invalid UTF-8 Sequence Start
| [\xE0-\xEF](?![\x80-\xBF]{2}) # Invalid UTF-8 Sequence Start
| [\xF0-\xF4](?![\x80-\xBF]{3}) # Invalid UTF-8 Sequence Start
| (?<=[\x0-\x7F\xF5-\xFF])[\x80-\xBF] # Invalid UTF-8 Sequence Middle
| (?<![\xC2-\xDF]|[\xE0-\xEF]|[\xE0-\xEF][\x80-\xBF]|[\xF0-\xF4]|[\xF0-\xF4][\x80-\xBF]|[\xF0-\xF4][\x80-\xBF]{2})[\x80-\xBF] # Overlong Sequence
| (?<=[\xE0-\xEF])[\x80-\xBF](?![\x80-\xBF]) # Short 3 byte sequence
| (?<=[\xF0-\xF4])[\x80-\xBF](?![\x80-\xBF]{2}) # Short 4 byte sequence
| (?<=[\xF0-\xF4][\x80-\xBF])[\x80-\xBF](?![\x80-\xBF]) # Short 4 byte sequence (2)
)/x';
$string = preg_replace($regex, '', $string);
$result = "";
$current;
$length = strlen($string);
for ($i=0; $i < $length; $i++)
{
$current = ord($string{$i});
if (($current == 0x9) ||
($current == 0xA) ||
($current == 0xD) ||
(($current >= 0x20) && ($current <= 0xD7FF)) ||
(($current >= 0xE000) && ($current <= 0xFFFD)) ||
(($current >= 0x10000) && ($current <= 0x10FFFF)))
{
$result .= chr($current);
}
else
{
$ret; // use this to strip invalid character(s)
// $ret .= " "; // use this to replace them with spaces
}
}
$string = $result;
}
return $string;
}
要删除Unicode基本语言平面之外的所有Unicode字符:
$str = preg_replace("/[^\\x00-\\xFFFF]/", "", $str);
与问题略有不同,但我正在做的是使用HtmlEncode(string),
伪代码如下:
var encoded = HtmlEncode(string);
encoded = Regex.Replace(encoded, "&#\d+?;", "");
var result = HtmlDecode(encoded);
输入和输出
"Headlight\x007E Bracket, { Cafe Racer<> Style, Stainless Steel 中文呢?"
"Headlight~ Bracket, { Cafe Racer<> Style, Stainless Steel 中文呢?"
我知道它不是完美的,但对我来说已经足够了。
对我来说,上面列出的所有UTF函数或替换方法都没有起作用。唯一有效的方法是明确允许我想要允许的字符。这可能是因为问题并不特别是UTF-8问题,尽管json_last_error_msg()告诉我是这样。
$text = preg_replace('/[^0-9a-zA-Z\.\-\,\/\ ]/m', '', $text);