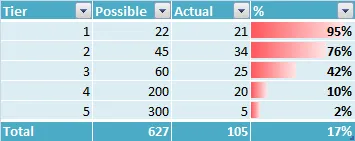
我不确定这个问题是否适合在Stack Overflow上提问,但我还是试着提出来了。我有一些数据如下所示:
你的问题不太清楚。如果你想通过包含你得到的额外数据来估算一个新的总百分比,你必须有与你的百分比相关联的数量,以便你可以创建一个有意义的加权平均值。
如果你想确定新的数据集是否与历史数据具有不同的分布,那么有几个测试主要是对落在特定值下面的值的累积实际与预期百分比进行晦涩的计算。关于比较两个总体分布的主题有很多文献。
对于成对样本,如果您不能对数据的分布做出任何假设,则Wilcoxon-Rank是一种标准方法。对于非成对数据,非参数统计存在,但需要进行深入研究。
步骤1:如果您的总百分比为17% → 30%,则实际(总共)105 → ~189。
步骤2:这个数字需要分配到实际列中的所有元素中。
从这里开始,事情变得非线性,我们需要一些公式来从可能的状态到达实际状态。而这需要是一个关于总数的函数。
即,function (possible, total (actual)) = actual。
如果我们能够得出上述结论,则它可能有效;)